Optimizing AUCMLoss on Imbalanced CIFAR10 Dataset (PESG)
Introduction
In this tutorial, you will learn how to quickly train a ResNet20
model by optimizing AUROC using our novel AUCMLoss
and PESG optimizer [Ref]
on a binary image classification task on Cifar10. After
completion of this tutorial, you should be able to use LibAUC to
train your own models on your own datasets.
Reference:
If you find this tutorial helpful in your work, please cite our library paper and the following papers:
@inproceedings{yuan2021large,
title={Large-scale robust deep auc maximization: A new surrogate loss and empirical studies on medical image classification},
author={Yuan, Zhuoning and Yan, Yan and Sonka, Milan and Yang, Tianbao},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={3040--3049},
year={2021} }
Install LibAUC
Let’s start with installing our library here. In this tutorial, we will use the lastest version for LibAUC by using pip install -U.
!pip install -U libauc
Importing LibAUC
Import required libraries to use
from libauc.losses import AUCMLoss
from libauc.optimizers import PESG
from libauc.models import resnet20 as ResNet20
from libauc.datasets import CIFAR10
from libauc.utils import ImbalancedDataGenerator
from libauc.sampler import DualSampler
from libauc.metrics import auc_roc_score
import torch
from PIL import Image
import numpy as np
import torchvision.transforms as transforms
from torch.utils.data import Dataset
from sklearn.metrics import roc_auc_score
Reproducibility
The following function set_all_seeds limits the number of sources
of randomness behaviors, such as model intialization, data shuffling,
etcs. However, completely reproducible results are not guaranteed
across PyTorch releases
[Ref].
def set_all_seeds(SEED):
# REPRODUCIBILITY
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_all_seeds(2023)
Image Dataset
Now we define the data input pipeline such as data
augmentations. In this tutorial, we use RandomCrop,
RandomHorizontalFlip.
class ImageDataset(Dataset):
def __init__(self, images, targets, image_size=32, crop_size=30, mode='train'):
self.images = images.astype(np.uint8)
self.targets = targets
self.mode = mode
self.transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.RandomCrop((crop_size, crop_size), padding=None),
transforms.RandomHorizontalFlip(),
transforms.Resize((image_size, image_size)),
])
self.transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((image_size, image_size)),
])
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx]
target = self.targets[idx]
image = Image.fromarray(image.astype('uint8'))
if self.mode == 'train':
image = self.transform_train(image)
else:
image = self.transform_test(image)
return image, target
Configuration
Hyper-Parameters
# HyperParameters
SEED = 123
BATCH_SIZE = 128
imratio = 0.1 # for demo
total_epochs = 100
decay_epochs = [50, 75]
lr = 0.1
margin = 1.0
epoch_decay = 0.003 # refers gamma in the paper
weight_decay = 0.0001
Loading datasets
# load data as numpy arrays
train_data, train_targets = CIFAR10(root='./data', train=True).as_array()
test_data, test_targets = CIFAR10(root='./data', train=False).as_array()
# generate imbalanced data
generator = ImbalancedDataGenerator(verbose=True, random_seed=0)
(train_images, train_labels) = generator.transform(train_data, train_targets, imratio=imratio)
(test_images, test_labels) = generator.transform(test_data, test_targets, imratio=0.5)
# data augmentations
trainSet = ImageDataset(train_images, train_labels)
trainSet_eval = ImageDataset(train_images, train_labels, mode='test')
testSet = ImageDataset(test_images, test_labels, mode='test')
Pretraining (Recommended)
Following the original paper, it’s recommended to start from a pretrained checkpoint with cross-entropy loss to significantly boost models’ performance. It includes a pre-training step with standard cross-entropy loss, and an AUROC maximization step that maximizes an AUROC surrogate loss of the pre-trained model.
from torch.optim import Adam
import warnings
warnings.filterwarnings('ignore')
load_pretrain = True
model = ResNet20(pretrained=False, last_activation=None, num_classes=1)
model = model.cuda()
loss_fn = torch.nn.BCELoss()
optimizer =Adam(model.parameters(), lr=1e-3, weight_decay=weight_decay)
trainloader = torch.utils.data.DataLoader(trainSet, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testSet, batch_size=BATCH_SIZE, shuffle=False, num_workers=2)
best_test = 0
for epoch in range(total_epochs):
if epoch in decay_epochs:
for param_group in optimizer.param_groups:
param_group['lr'] = 0.1 * param_group['lr']
model.train()
for idx, (data, targets) in enumerate(trainloader):
data, targets = data.cuda(), targets.cuda()
y_pred = model(data)
y_prob = torch.sigmoid(y_pred)
loss = loss_fn(y_prob, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
######***evaluation***####
# evaluation on test sets
model.eval()
test_pred_list, test_true_list = [], []
with torch.no_grad():
for j, data in enumerate(testloader):
test_data, test_targets = data
test_data = test_data.cuda()
y_pred = model(test_data)
y_prob = torch.sigmoid(y_pred)
test_pred_list.append(y_prob.cpu().detach().numpy())
test_true_list.append(test_targets.numpy())
test_true = np.concatenate(test_true_list)
test_pred = np.concatenate(test_pred_list)
test_auc = auc_roc_score(test_true, test_pred)
if best_test < test_auc:
best_test = test_auc
torch.save(model.state_dict(), 'ce_pretrained_model.pth')
model.train()
print("epoch: %s, test_auc: %.4f, best_test_auc: %.4f, lr: %.4f"%(epoch, test_auc, best_test, optimizer.param_groups[0]['lr'] ))
epoch: 0, test_auc: 0.6803, best_test_auc: 0.6803, lr: 0.0010
epoch: 1, test_auc: 0.6997, best_test_auc: 0.6997, lr: 0.0010
epoch: 2, test_auc: 0.7218, best_test_auc: 0.7218, lr: 0.0010
epoch: 3, test_auc: 0.7204, best_test_auc: 0.7218, lr: 0.0010
epoch: 4, test_auc: 0.7074, best_test_auc: 0.7218, lr: 0.0010
epoch: 5, test_auc: 0.7808, best_test_auc: 0.7808, lr: 0.0010
epoch: 6, test_auc: 0.8012, best_test_auc: 0.8012, lr: 0.0010
epoch: 7, test_auc: 0.8222, best_test_auc: 0.8222, lr: 0.0010
epoch: 8, test_auc: 0.8300, best_test_auc: 0.8300, lr: 0.0010
epoch: 9, test_auc: 0.7981, best_test_auc: 0.8300, lr: 0.0010
epoch: 10, test_auc: 0.8193, best_test_auc: 0.8300, lr: 0.0010
epoch: 11, test_auc: 0.8430, best_test_auc: 0.8430, lr: 0.0010
epoch: 12, test_auc: 0.8397, best_test_auc: 0.8430, lr: 0.0010
epoch: 13, test_auc: 0.8459, best_test_auc: 0.8459, lr: 0.0010
epoch: 14, test_auc: 0.8370, best_test_auc: 0.8459, lr: 0.0010
epoch: 15, test_auc: 0.8327, best_test_auc: 0.8459, lr: 0.0010
epoch: 16, test_auc: 0.8725, best_test_auc: 0.8725, lr: 0.0010
epoch: 17, test_auc: 0.8674, best_test_auc: 0.8725, lr: 0.0010
epoch: 18, test_auc: 0.8757, best_test_auc: 0.8757, lr: 0.0010
epoch: 19, test_auc: 0.8561, best_test_auc: 0.8757, lr: 0.0010
epoch: 20, test_auc: 0.8768, best_test_auc: 0.8768, lr: 0.0010
epoch: 21, test_auc: 0.8819, best_test_auc: 0.8819, lr: 0.0010
epoch: 22, test_auc: 0.8649, best_test_auc: 0.8819, lr: 0.0010
epoch: 23, test_auc: 0.8693, best_test_auc: 0.8819, lr: 0.0010
epoch: 24, test_auc: 0.8849, best_test_auc: 0.8849, lr: 0.0010
epoch: 25, test_auc: 0.8523, best_test_auc: 0.8849, lr: 0.0010
epoch: 26, test_auc: 0.8675, best_test_auc: 0.8849, lr: 0.0010
epoch: 27, test_auc: 0.8778, best_test_auc: 0.8849, lr: 0.0010
epoch: 28, test_auc: 0.8879, best_test_auc: 0.8879, lr: 0.0010
epoch: 29, test_auc: 0.8932, best_test_auc: 0.8932, lr: 0.0010
epoch: 30, test_auc: 0.8883, best_test_auc: 0.8932, lr: 0.0010
epoch: 31, test_auc: 0.8897, best_test_auc: 0.8932, lr: 0.0010
epoch: 32, test_auc: 0.8898, best_test_auc: 0.8932, lr: 0.0010
epoch: 33, test_auc: 0.8950, best_test_auc: 0.8950, lr: 0.0010
epoch: 34, test_auc: 0.9040, best_test_auc: 0.9040, lr: 0.0010
epoch: 35, test_auc: 0.8902, best_test_auc: 0.9040, lr: 0.0010
epoch: 36, test_auc: 0.8934, best_test_auc: 0.9040, lr: 0.0010
epoch: 37, test_auc: 0.8827, best_test_auc: 0.9040, lr: 0.0010
epoch: 38, test_auc: 0.9046, best_test_auc: 0.9046, lr: 0.0010
epoch: 39, test_auc: 0.8939, best_test_auc: 0.9046, lr: 0.0010
epoch: 40, test_auc: 0.8860, best_test_auc: 0.9046, lr: 0.0010
epoch: 41, test_auc: 0.9030, best_test_auc: 0.9046, lr: 0.0010
epoch: 42, test_auc: 0.9002, best_test_auc: 0.9046, lr: 0.0010
epoch: 43, test_auc: 0.8991, best_test_auc: 0.9046, lr: 0.0010
epoch: 44, test_auc: 0.9043, best_test_auc: 0.9046, lr: 0.0010
epoch: 45, test_auc: 0.9052, best_test_auc: 0.9052, lr: 0.0010
epoch: 46, test_auc: 0.9006, best_test_auc: 0.9052, lr: 0.0010
epoch: 47, test_auc: 0.8983, best_test_auc: 0.9052, lr: 0.0010
epoch: 48, test_auc: 0.9057, best_test_auc: 0.9057, lr: 0.0010
epoch: 49, test_auc: 0.8986, best_test_auc: 0.9057, lr: 0.0010
epoch: 50, test_auc: 0.9167, best_test_auc: 0.9167, lr: 0.0001
epoch: 51, test_auc: 0.9163, best_test_auc: 0.9167, lr: 0.0001
epoch: 52, test_auc: 0.9172, best_test_auc: 0.9172, lr: 0.0001
epoch: 53, test_auc: 0.9176, best_test_auc: 0.9176, lr: 0.0001
epoch: 54, test_auc: 0.9158, best_test_auc: 0.9176, lr: 0.0001
epoch: 55, test_auc: 0.9110, best_test_auc: 0.9176, lr: 0.0001
epoch: 56, test_auc: 0.9149, best_test_auc: 0.9176, lr: 0.0001
epoch: 57, test_auc: 0.9097, best_test_auc: 0.9176, lr: 0.0001
epoch: 58, test_auc: 0.9147, best_test_auc: 0.9176, lr: 0.0001
epoch: 59, test_auc: 0.9113, best_test_auc: 0.9176, lr: 0.0001
epoch: 60, test_auc: 0.9157, best_test_auc: 0.9176, lr: 0.0001
epoch: 61, test_auc: 0.9094, best_test_auc: 0.9176, lr: 0.0001
epoch: 62, test_auc: 0.9156, best_test_auc: 0.9176, lr: 0.0001
epoch: 63, test_auc: 0.9086, best_test_auc: 0.9176, lr: 0.0001
epoch: 64, test_auc: 0.9110, best_test_auc: 0.9176, lr: 0.0001
epoch: 65, test_auc: 0.9125, best_test_auc: 0.9176, lr: 0.0001
epoch: 66, test_auc: 0.9111, best_test_auc: 0.9176, lr: 0.0001
epoch: 67, test_auc: 0.9093, best_test_auc: 0.9176, lr: 0.0001
epoch: 68, test_auc: 0.9100, best_test_auc: 0.9176, lr: 0.0001
epoch: 69, test_auc: 0.9055, best_test_auc: 0.9176, lr: 0.0001
epoch: 70, test_auc: 0.9085, best_test_auc: 0.9176, lr: 0.0001
epoch: 71, test_auc: 0.9059, best_test_auc: 0.9176, lr: 0.0001
epoch: 72, test_auc: 0.9061, best_test_auc: 0.9176, lr: 0.0001
epoch: 73, test_auc: 0.9092, best_test_auc: 0.9176, lr: 0.0001
epoch: 74, test_auc: 0.9068, best_test_auc: 0.9176, lr: 0.0001
epoch: 75, test_auc: 0.9076, best_test_auc: 0.9176, lr: 0.0000
epoch: 76, test_auc: 0.9065, best_test_auc: 0.9176, lr: 0.0000
epoch: 77, test_auc: 0.9080, best_test_auc: 0.9176, lr: 0.0000
epoch: 78, test_auc: 0.9066, best_test_auc: 0.9176, lr: 0.0000
epoch: 79, test_auc: 0.9028, best_test_auc: 0.9176, lr: 0.0000
epoch: 80, test_auc: 0.9066, best_test_auc: 0.9176, lr: 0.0000
epoch: 81, test_auc: 0.9077, best_test_auc: 0.9176, lr: 0.0000
epoch: 82, test_auc: 0.9101, best_test_auc: 0.9176, lr: 0.0000
epoch: 83, test_auc: 0.9050, best_test_auc: 0.9176, lr: 0.0000
epoch: 84, test_auc: 0.9039, best_test_auc: 0.9176, lr: 0.0000
epoch: 85, test_auc: 0.9065, best_test_auc: 0.9176, lr: 0.0000
epoch: 86, test_auc: 0.9083, best_test_auc: 0.9176, lr: 0.0000
epoch: 87, test_auc: 0.9071, best_test_auc: 0.9176, lr: 0.0000
epoch: 88, test_auc: 0.9057, best_test_auc: 0.9176, lr: 0.0000
epoch: 89, test_auc: 0.9022, best_test_auc: 0.9176, lr: 0.0000
epoch: 90, test_auc: 0.9016, best_test_auc: 0.9176, lr: 0.0000
epoch: 91, test_auc: 0.9059, best_test_auc: 0.9176, lr: 0.0000
epoch: 92, test_auc: 0.9075, best_test_auc: 0.9176, lr: 0.0000
epoch: 93, test_auc: 0.9073, best_test_auc: 0.9176, lr: 0.0000
epoch: 94, test_auc: 0.9050, best_test_auc: 0.9176, lr: 0.0000
epoch: 95, test_auc: 0.9046, best_test_auc: 0.9176, lr: 0.0000
epoch: 96, test_auc: 0.9051, best_test_auc: 0.9176, lr: 0.0000
epoch: 97, test_auc: 0.9021, best_test_auc: 0.9176, lr: 0.0000
epoch: 98, test_auc: 0.9028, best_test_auc: 0.9176, lr: 0.0000
epoch: 99, test_auc: 0.9056, best_test_auc: 0.9176, lr: 0.0000
Optimizing AUC Loss
We define dataset, DualSampler and dataloader here.
# oversampling minority class, you can tune it in (0, 0.5]
# e.g., sampling_rate=0.2 is that num of positive samples in mini-batch is sampling_rate*batch_size=13
sampling_rate = 0.2
# dataloaders
sampler = DualSampler(trainSet, BATCH_SIZE, sampling_rate=sampling_rate)
trainloader = torch.utils.data.DataLoader(trainSet, batch_size=BATCH_SIZE, sampler=sampler, num_workers=2)
trainloader_eval = torch.utils.data.DataLoader(trainSet_eval, batch_size=BATCH_SIZE, shuffle=False, num_workers=2)
testloader = torch.utils.data.DataLoader(testSet, batch_size=BATCH_SIZE, shuffle=False, num_workers=2)
Creating models & AUC Optimizer
# You can include sigmoid/l2 activations on model's outputs before computing loss
model = ResNet20(pretrained=False, last_activation=None, num_classes=1)
model = model.cuda()
# load pretrained model
if load_pretrain:
PATH = 'ce_pretrained_model.pth'
state_dict = torch.load(PATH)
filtered = {k:v for k,v in state_dict.items() if 'linear' not in k}
msg = model.load_state_dict(filtered, False)
print(msg)
model.linear.reset_parameters()
# You can also pass Loss.a, Loss.b, Loss.alpha to optimizer (for old version users)
loss_fn = AUCMLoss()
optimizer = PESG(model.parameters(),
loss_fn=loss_fn,
lr=lr,
momentum=0.9,
margin=margin,
epoch_decay=epoch_decay,
weight_decay=weight_decay)
Training
Now it’s time for training. And we evaluate AUC performance after every epoch.
print ('Start Training')
print ('-'*30)
train_log = []
test_log = []
best_test = 0
for epoch in range(total_epochs):
if epoch in decay_epochs:
optimizer.update_regularizer(decay_factor=10) # decrease learning rate by 10x & update regularizer
train_loss = []
model.train()
for data, targets in trainloader:
data, targets = data.cuda(), targets.cuda()
y_pred = model(data)
y_pred = torch.sigmoid(y_pred)
loss = loss_fn(y_pred, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
# evaluation on train & test sets
model.eval()
train_pred_list = []
train_true_list = []
with torch.no_grad():
for train_data, train_targets in trainloader_eval:
train_data = train_data.cuda()
train_pred = model(train_data)
train_pred_list.append(train_pred.cpu().detach().numpy())
train_true_list.append(train_targets.numpy())
train_true = np.concatenate(train_true_list)
train_pred = np.concatenate(train_pred_list)
train_auc = auc_roc_score(train_true, train_pred)
train_loss = np.mean(train_loss)
test_pred_list = []
test_true_list = []
with torch.no_grad():
for test_data, test_targets in testloader:
test_data = test_data.cuda()
test_pred = model(test_data)
test_pred_list.append(test_pred.cpu().detach().numpy())
test_true_list.append(test_targets.numpy())
test_true = np.concatenate(test_true_list)
test_pred = np.concatenate(test_pred_list)
test_auc = auc_roc_score(test_true, test_pred)
if best_test < test_auc:
best_test = test_auc
model.train()
# print results
print("epoch: %s, train_loss: %.4f, train_auc: %.4f, test_auc: %.4f, best_test_auc: %.4f, lr: %.4f"%(epoch, train_loss, train_auc, test_auc, best_test, optimizer.lr ))
train_log.append(train_auc)
test_log.append(test_auc)
Start Training
------------------------------
epoch: 0, train_loss: 0.0267, train_auc: 0.9899, test_auc: 0.9184, best_test_auc: 0.9184, lr: 0.1000
epoch: 1, train_loss: 0.0114, train_auc: 0.9910, test_auc: 0.9169, best_test_auc: 0.9184, lr: 0.1000
epoch: 2, train_loss: 0.0101, train_auc: 0.9897, test_auc: 0.9160, best_test_auc: 0.9184, lr: 0.1000
epoch: 3, train_loss: 0.0099, train_auc: 0.9916, test_auc: 0.9172, best_test_auc: 0.9184, lr: 0.1000
epoch: 4, train_loss: 0.0097, train_auc: 0.9905, test_auc: 0.9153, best_test_auc: 0.9184, lr: 0.1000
epoch: 5, train_loss: 0.0096, train_auc: 0.9888, test_auc: 0.9124, best_test_auc: 0.9184, lr: 0.1000
epoch: 6, train_loss: 0.0095, train_auc: 0.9918, test_auc: 0.9159, best_test_auc: 0.9184, lr: 0.1000
epoch: 7, train_loss: 0.0097, train_auc: 0.9892, test_auc: 0.9109, best_test_auc: 0.9184, lr: 0.1000
epoch: 8, train_loss: 0.0097, train_auc: 0.9906, test_auc: 0.9097, best_test_auc: 0.9184, lr: 0.1000
epoch: 9, train_loss: 0.0093, train_auc: 0.9864, test_auc: 0.9061, best_test_auc: 0.9184, lr: 0.1000
epoch: 10, train_loss: 0.0097, train_auc: 0.9878, test_auc: 0.9090, best_test_auc: 0.9184, lr: 0.1000
epoch: 11, train_loss: 0.0101, train_auc: 0.9896, test_auc: 0.9052, best_test_auc: 0.9184, lr: 0.1000
epoch: 12, train_loss: 0.0103, train_auc: 0.9908, test_auc: 0.9131, best_test_auc: 0.9184, lr: 0.1000
epoch: 13, train_loss: 0.0105, train_auc: 0.9855, test_auc: 0.9024, best_test_auc: 0.9184, lr: 0.1000
epoch: 14, train_loss: 0.0113, train_auc: 0.9872, test_auc: 0.9063, best_test_auc: 0.9184, lr: 0.1000
epoch: 15, train_loss: 0.0119, train_auc: 0.9810, test_auc: 0.9037, best_test_auc: 0.9184, lr: 0.1000
epoch: 16, train_loss: 0.0128, train_auc: 0.9784, test_auc: 0.8932, best_test_auc: 0.9184, lr: 0.1000
epoch: 17, train_loss: 0.0138, train_auc: 0.9787, test_auc: 0.8965, best_test_auc: 0.9184, lr: 0.1000
epoch: 18, train_loss: 0.0158, train_auc: 0.9867, test_auc: 0.9064, best_test_auc: 0.9184, lr: 0.1000
epoch: 19, train_loss: 0.0169, train_auc: 0.9600, test_auc: 0.8785, best_test_auc: 0.9184, lr: 0.1000
epoch: 20, train_loss: 0.0194, train_auc: 0.9571, test_auc: 0.8737, best_test_auc: 0.9184, lr: 0.1000
epoch: 21, train_loss: 0.0213, train_auc: 0.9612, test_auc: 0.8959, best_test_auc: 0.9184, lr: 0.1000
epoch: 22, train_loss: 0.0230, train_auc: 0.9330, test_auc: 0.8631, best_test_auc: 0.9184, lr: 0.1000
epoch: 23, train_loss: 0.0244, train_auc: 0.9438, test_auc: 0.8753, best_test_auc: 0.9184, lr: 0.1000
epoch: 24, train_loss: 0.0266, train_auc: 0.9543, test_auc: 0.8911, best_test_auc: 0.9184, lr: 0.1000
epoch: 25, train_loss: 0.0279, train_auc: 0.9658, test_auc: 0.9005, best_test_auc: 0.9184, lr: 0.1000
epoch: 26, train_loss: 0.0293, train_auc: 0.9400, test_auc: 0.8764, best_test_auc: 0.9184, lr: 0.1000
epoch: 27, train_loss: 0.0299, train_auc: 0.9253, test_auc: 0.8688, best_test_auc: 0.9184, lr: 0.1000
epoch: 28, train_loss: 0.0318, train_auc: 0.8793, test_auc: 0.8370, best_test_auc: 0.9184, lr: 0.1000
epoch: 29, train_loss: 0.0323, train_auc: 0.9393, test_auc: 0.8816, best_test_auc: 0.9184, lr: 0.1000
epoch: 30, train_loss: 0.0332, train_auc: 0.9130, test_auc: 0.8671, best_test_auc: 0.9184, lr: 0.1000
epoch: 31, train_loss: 0.0334, train_auc: 0.9509, test_auc: 0.8957, best_test_auc: 0.9184, lr: 0.1000
epoch: 32, train_loss: 0.0333, train_auc: 0.9290, test_auc: 0.8691, best_test_auc: 0.9184, lr: 0.1000
epoch: 33, train_loss: 0.0327, train_auc: 0.9064, test_auc: 0.8516, best_test_auc: 0.9184, lr: 0.1000
epoch: 34, train_loss: 0.0338, train_auc: 0.9227, test_auc: 0.8604, best_test_auc: 0.9184, lr: 0.1000
epoch: 35, train_loss: 0.0337, train_auc: 0.9422, test_auc: 0.8883, best_test_auc: 0.9184, lr: 0.1000
epoch: 36, train_loss: 0.0342, train_auc: 0.8942, test_auc: 0.8326, best_test_auc: 0.9184, lr: 0.1000
epoch: 37, train_loss: 0.0330, train_auc: 0.9100, test_auc: 0.8616, best_test_auc: 0.9184, lr: 0.1000
epoch: 38, train_loss: 0.0342, train_auc: 0.9492, test_auc: 0.8996, best_test_auc: 0.9184, lr: 0.1000
epoch: 39, train_loss: 0.0336, train_auc: 0.8824, test_auc: 0.8230, best_test_auc: 0.9184, lr: 0.1000
epoch: 40, train_loss: 0.0335, train_auc: 0.9356, test_auc: 0.8738, best_test_auc: 0.9184, lr: 0.1000
epoch: 41, train_loss: 0.0320, train_auc: 0.9479, test_auc: 0.8894, best_test_auc: 0.9184, lr: 0.1000
epoch: 42, train_loss: 0.0348, train_auc: 0.9194, test_auc: 0.8692, best_test_auc: 0.9184, lr: 0.1000
epoch: 43, train_loss: 0.0332, train_auc: 0.9236, test_auc: 0.8669, best_test_auc: 0.9184, lr: 0.1000
epoch: 44, train_loss: 0.0330, train_auc: 0.9490, test_auc: 0.8934, best_test_auc: 0.9184, lr: 0.1000
epoch: 45, train_loss: 0.0333, train_auc: 0.9212, test_auc: 0.8749, best_test_auc: 0.9184, lr: 0.1000
epoch: 46, train_loss: 0.0329, train_auc: 0.9417, test_auc: 0.8895, best_test_auc: 0.9184, lr: 0.1000
epoch: 47, train_loss: 0.0329, train_auc: 0.8863, test_auc: 0.8444, best_test_auc: 0.9184, lr: 0.1000
epoch: 48, train_loss: 0.0321, train_auc: 0.9225, test_auc: 0.8804, best_test_auc: 0.9184, lr: 0.1000
epoch: 49, train_loss: 0.0328, train_auc: 0.9447, test_auc: 0.8935, best_test_auc: 0.9184, lr: 0.1000
Reducing learning rate to 0.01000 @ T=12100!
Updating regularizer @ T=12100!
epoch: 50, train_loss: 0.0189, train_auc: 0.9778, test_auc: 0.9187, best_test_auc: 0.9187, lr: 0.0100
epoch: 51, train_loss: 0.0141, train_auc: 0.9848, test_auc: 0.9249, best_test_auc: 0.9249, lr: 0.0100
epoch: 52, train_loss: 0.0122, train_auc: 0.9872, test_auc: 0.9263, best_test_auc: 0.9263, lr: 0.0100
epoch: 53, train_loss: 0.0112, train_auc: 0.9873, test_auc: 0.9251, best_test_auc: 0.9263, lr: 0.0100
epoch: 54, train_loss: 0.0105, train_auc: 0.9887, test_auc: 0.9248, best_test_auc: 0.9263, lr: 0.0100
epoch: 55, train_loss: 0.0097, train_auc: 0.9884, test_auc: 0.9237, best_test_auc: 0.9263, lr: 0.0100
epoch: 56, train_loss: 0.0090, train_auc: 0.9907, test_auc: 0.9243, best_test_auc: 0.9263, lr: 0.0100
epoch: 57, train_loss: 0.0083, train_auc: 0.9900, test_auc: 0.9201, best_test_auc: 0.9263, lr: 0.0100
epoch: 58, train_loss: 0.0080, train_auc: 0.9901, test_auc: 0.9196, best_test_auc: 0.9263, lr: 0.0100
epoch: 59, train_loss: 0.0076, train_auc: 0.9910, test_auc: 0.9212, best_test_auc: 0.9263, lr: 0.0100
epoch: 60, train_loss: 0.0075, train_auc: 0.9913, test_auc: 0.9207, best_test_auc: 0.9263, lr: 0.0100
epoch: 61, train_loss: 0.0068, train_auc: 0.9924, test_auc: 0.9195, best_test_auc: 0.9263, lr: 0.0100
epoch: 62, train_loss: 0.0066, train_auc: 0.9921, test_auc: 0.9188, best_test_auc: 0.9263, lr: 0.0100
epoch: 63, train_loss: 0.0062, train_auc: 0.9926, test_auc: 0.9207, best_test_auc: 0.9263, lr: 0.0100
epoch: 64, train_loss: 0.0059, train_auc: 0.9926, test_auc: 0.9160, best_test_auc: 0.9263, lr: 0.0100
epoch: 65, train_loss: 0.0056, train_auc: 0.9928, test_auc: 0.9186, best_test_auc: 0.9263, lr: 0.0100
epoch: 66, train_loss: 0.0053, train_auc: 0.9920, test_auc: 0.9173, best_test_auc: 0.9263, lr: 0.0100
epoch: 67, train_loss: 0.0054, train_auc: 0.9924, test_auc: 0.9178, best_test_auc: 0.9263, lr: 0.0100
epoch: 68, train_loss: 0.0051, train_auc: 0.9936, test_auc: 0.9175, best_test_auc: 0.9263, lr: 0.0100
epoch: 69, train_loss: 0.0048, train_auc: 0.9930, test_auc: 0.9150, best_test_auc: 0.9263, lr: 0.0100
epoch: 70, train_loss: 0.0046, train_auc: 0.9936, test_auc: 0.9152, best_test_auc: 0.9263, lr: 0.0100
epoch: 71, train_loss: 0.0046, train_auc: 0.9937, test_auc: 0.9127, best_test_auc: 0.9263, lr: 0.0100
epoch: 72, train_loss: 0.0044, train_auc: 0.9940, test_auc: 0.9161, best_test_auc: 0.9263, lr: 0.0100
epoch: 73, train_loss: 0.0046, train_auc: 0.9939, test_auc: 0.9163, best_test_auc: 0.9263, lr: 0.0100
epoch: 74, train_loss: 0.0042, train_auc: 0.9931, test_auc: 0.9123, best_test_auc: 0.9263, lr: 0.0100
Reducing learning rate to 0.00100 @ T=18150!
Updating regularizer @ T=18150!
epoch: 75, train_loss: 0.0041, train_auc: 0.9938, test_auc: 0.9134, best_test_auc: 0.9263, lr: 0.0010
epoch: 76, train_loss: 0.0040, train_auc: 0.9939, test_auc: 0.9134, best_test_auc: 0.9263, lr: 0.0010
epoch: 77, train_loss: 0.0037, train_auc: 0.9939, test_auc: 0.9134, best_test_auc: 0.9263, lr: 0.0010
epoch: 78, train_loss: 0.0039, train_auc: 0.9937, test_auc: 0.9125, best_test_auc: 0.9263, lr: 0.0010
epoch: 79, train_loss: 0.0038, train_auc: 0.9942, test_auc: 0.9141, best_test_auc: 0.9263, lr: 0.0010
epoch: 80, train_loss: 0.0039, train_auc: 0.9939, test_auc: 0.9137, best_test_auc: 0.9263, lr: 0.0010
epoch: 81, train_loss: 0.0038, train_auc: 0.9940, test_auc: 0.9137, best_test_auc: 0.9263, lr: 0.0010
epoch: 82, train_loss: 0.0037, train_auc: 0.9944, test_auc: 0.9142, best_test_auc: 0.9263, lr: 0.0010
epoch: 83, train_loss: 0.0036, train_auc: 0.9939, test_auc: 0.9135, best_test_auc: 0.9263, lr: 0.0010
epoch: 84, train_loss: 0.0037, train_auc: 0.9942, test_auc: 0.9140, best_test_auc: 0.9263, lr: 0.0010
epoch: 85, train_loss: 0.0036, train_auc: 0.9944, test_auc: 0.9140, best_test_auc: 0.9263, lr: 0.0010
epoch: 86, train_loss: 0.0035, train_auc: 0.9941, test_auc: 0.9133, best_test_auc: 0.9263, lr: 0.0010
epoch: 87, train_loss: 0.0037, train_auc: 0.9943, test_auc: 0.9133, best_test_auc: 0.9263, lr: 0.0010
epoch: 88, train_loss: 0.0035, train_auc: 0.9944, test_auc: 0.9134, best_test_auc: 0.9263, lr: 0.0010
epoch: 89, train_loss: 0.0036, train_auc: 0.9942, test_auc: 0.9131, best_test_auc: 0.9263, lr: 0.0010
epoch: 90, train_loss: 0.0034, train_auc: 0.9943, test_auc: 0.9120, best_test_auc: 0.9263, lr: 0.0010
epoch: 91, train_loss: 0.0036, train_auc: 0.9942, test_auc: 0.9123, best_test_auc: 0.9263, lr: 0.0010
epoch: 92, train_loss: 0.0035, train_auc: 0.9943, test_auc: 0.9127, best_test_auc: 0.9263, lr: 0.0010
epoch: 93, train_loss: 0.0034, train_auc: 0.9941, test_auc: 0.9133, best_test_auc: 0.9263, lr: 0.0010
epoch: 94, train_loss: 0.0036, train_auc: 0.9942, test_auc: 0.9122, best_test_auc: 0.9263, lr: 0.0010
epoch: 95, train_loss: 0.0033, train_auc: 0.9944, test_auc: 0.9125, best_test_auc: 0.9263, lr: 0.0010
epoch: 96, train_loss: 0.0034, train_auc: 0.9943, test_auc: 0.9133, best_test_auc: 0.9263, lr: 0.0010
epoch: 97, train_loss: 0.0034, train_auc: 0.9943, test_auc: 0.9123, best_test_auc: 0.9263, lr: 0.0010
epoch: 98, train_loss: 0.0035, train_auc: 0.9945, test_auc: 0.9137, best_test_auc: 0.9263, lr: 0.0010
epoch: 99, train_loss: 0.0034, train_auc: 0.9943, test_auc: 0.9119, best_test_auc: 0.9263, lr: 0.0010
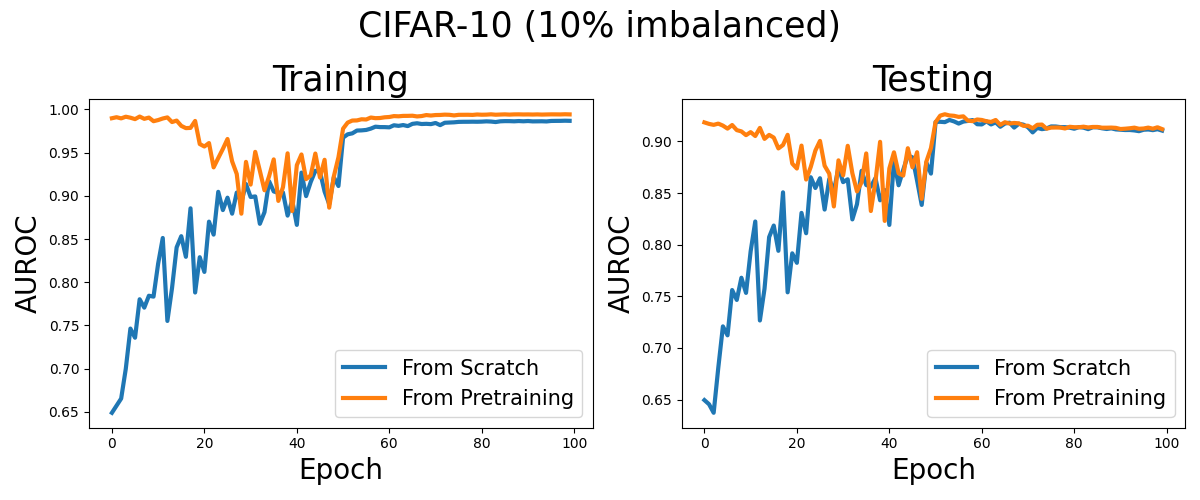
Visualization
Now, let’s have a look at the learning curves for optimizing AUROC from scratch and from a pretrained model with cross entropy loss.
import matplotlib.pyplot as plt
train_log_scratch = [0.6487864241987756, 0.6570376953546992, 0.6652891969751531, 0.6997062441483615, 0.7463313359740728, 0.7357006769895571, 0.7802633201296363, 0.7705517536910335, 0.7843153619013324, 0.7833184587684552, 0.8215275837234426, 0.8512112351458407, 0.7551542239827151, 0.7930894346416998, 0.8403568815268277, 0.8532969679510263, 0.8294249405833631, 0.8855697515304286, 0.78807505221462, 0.8289326179330212, 0.8119374576881526, 0.870111199135758, 0.8550965286280157, 0.9046458768455168, 0.8835233489377026, 0.8978948001440403, 0.879345790421318, 0.9038241699675909, 0.8927085199855959, 0.9137222038170687, 0.8986654807346055, 0.899318314728124, 0.8676161253150882, 0.8810589701116314, 0.9168891897731364, 0.9050961325171047, 0.9034263089665105, 0.9039333381346778, 0.8770988260712999, 0.894781469211379, 0.8663913431760892, 0.9268936694274399, 0.8996783867482894, 0.915994987396471, 0.929009859560677, 0.928035664386028, 0.9050354555275475, 0.8903964061937343, 0.9215445012603527, 0.9113632985235866, 0.9673894418437161, 0.9712597479294202, 0.9723788260712999, 0.9756220813827873, 0.9758165790421317, 0.9763222758372344, 0.9778468347137198, 0.9800894202376665, 0.9796207850198057, 0.9795943680230466, 0.9793308318329131, 0.98173389989197, 0.981050140439323, 0.9819711199135758, 0.9807803312927621, 0.9833618941303564, 0.9840564638098668, 0.9831874540871446, 0.9834106013683832, 0.9830627583723442, 0.9843784155563557, 0.9818939575081023, 0.9846380842635938, 0.9848955851638459, 0.985140907454087, 0.9856526611451206, 0.9857646957148001, 0.985784616492618, 0.9858735181850918, 0.9857995966870723, 0.9859454375225063, 0.9862662873604608, 0.9860312855599568, 0.9854559452646742, 0.9863081166726684, 0.9865275477133597, 0.9865129420237667, 0.9863067050774218, 0.9866201512423478, 0.9863383363341736, 0.986646618653223, 0.9862285487936622, 0.9862882679150162, 0.9863598127475695, 0.9861665394310407, 0.9867232841195536, 0.986805358300324, 0.9868380842635938, 0.9870069139359021, 0.9868661289160965]
test_log_scratch = [0.64954048, 0.6455573, 0.63726404, 0.6808524800000001, 0.72093944, 0.71224636, 0.7561244, 0.7465077000000001, 0.7680155999999999, 0.7533547600000001, 0.7935768799999999, 0.82246204, 0.7266309400000002, 0.75730204, 0.8073705600000001, 0.8185382600000001, 0.7940768, 0.8506930199999998, 0.7538938400000001, 0.7916545600000001, 0.78242764, 0.83077196, 0.81109932, 0.86531856, 0.85488648, 0.8643425200000001, 0.83400484, 0.8635066, 0.85143188, 0.8750814800000001, 0.86054532, 0.86332512, 0.8245006000000001, 0.83921446, 0.87151104, 0.8577713600000001, 0.85627144, 0.86444628, 0.8429737200000001, 0.85292974, 0.81913848, 0.8814284400000001, 0.8575169999999999, 0.87243962, 0.88622472, 0.8845532, 0.8620859999999999, 0.83851166, 0.8795108, 0.86881428, 0.91882244, 0.91899608, 0.9186357199999998, 0.9207326799999999, 0.9193346, 0.9172649600000001, 0.9191856, 0.9198186000000002, 0.9206534800000001, 0.91662526, 0.91642482, 0.9194517199999999, 0.9164139400000001, 0.9184157399999999, 0.9142051, 0.91731436, 0.91813376, 0.9133845600000001, 0.91703996, 0.91620514, 0.9136835799999999, 0.9087101599999999, 0.9130744, 0.9118543, 0.91251262, 0.91449428, 0.9144272400000001, 0.9138009599999999, 0.9138013400000001, 0.91329232, 0.9122549799999999, 0.9137974199999999, 0.9133186, 0.91187654, 0.91368122, 0.9136239, 0.9126864, 0.9120131200000001, 0.91264694, 0.9115934600000001, 0.9113091999999999, 0.91100668, 0.9110379000000001, 0.91061902, 0.9098951200000001, 0.9112703600000001, 0.91152912, 0.9108944800000001, 0.9118080400000002, 0.9104458400000001]
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(12,5))
plt.suptitle('CIFAR-10 (10% imbalanced)',fontsize=25)
x=np.arange(len(train_log))
ax0.plot(x, train_log_scratch, label='From Scratch', linewidth=3)
ax0.plot(x, train_log, label='From Pretraining', linewidth=3)
ax0.set_title('Training',fontsize=25)
ax1.plot(x, test_log_scratch, label='From Scratch', linewidth=3)
ax1.plot(x, test_log, label='From Pretraining', linewidth=3)
ax1.set_title('Testing',fontsize=25)
ax0.legend(fontsize=15)
ax1.legend(fontsize=15)
ax0.set_ylabel('AUROC', fontsize=20)
ax0.set_xlabel('Epoch', fontsize=20)
ax1.set_ylabel('AUROC', fontsize=20)
ax1.set_xlabel('Epoch', fontsize=20)
plt.tight_layout()