Optimizing CompositionalAUCLoss on Imbalanced CIFAR10 Dataset (PDSCA)
Author: Zhuoning Yuan, Tianbao Yang
Introduction
In this tutorial, you will learn how to quickly train a ResNet20 model
by optimizing AUROC using our novel CompositionalAUCLoss and PDSCA optimizer [Ref] on
a binary image classification task on Cifar10. After completion of
this tutorial, you should be able to use LibAUC to train your own
models on your own datasets.
Reference:
If you find this tutorial helpful in your work, please cite our library paper and the following papers:
@inproceedings{yuan2022compositional,
title={Compositional Training for End-to-End Deep AUC Maximization},
author={Zhuoning Yuan and Zhishuai Guo and Nitesh Chawla and Tianbao Yang},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=gPvB4pdu_Z} }
Install LibAUC
Let’s start with installing our library here. In this tutorial, we will use the lastest version for LibAUC by using pip install -U.
!pip install -U libauc
Importing LibAUC
from libauc.losses import CompositionalAUCLoss
from libauc.optimizers import PDSCA
from libauc.models import resnet20 as ResNet20
from libauc.datasets import CIFAR10, CIFAR100, STL10, CAT_VS_DOG
from libauc.utils import ImbalancedDataGenerator
from libauc.sampler import DualSampler
from libauc.metrics import auc_roc_score
import torch
from PIL import Image
import numpy as np
import torchvision.transforms as transforms
from torch.utils.data import Dataset
Reproducibility
The following function set_all_seeds limits the number of sources
of randomness behaviors, such as model intialization, data shuffling,
etcs. However, completely reproducible results are not guaranteed
across PyTorch releases
[Ref].
def set_all_seeds(SEED):
# REPRODUCIBILITY
torch.manual_seed(SEED)
np.random.seed(SEED)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
Image Dataset
Now we define the data input pipeline such as data
augmentations. In this tutorial, we use RandomCrop,
RandomHorizontalFlip as stated in the original paper.
class ImageDataset(Dataset):
def __init__(self, images, targets, image_size=32, crop_size=30, mode='train'):
self.images = images.astype(np.uint8)
self.targets = targets
self.mode = mode
self.transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.RandomCrop((crop_size, crop_size), padding=None),
transforms.RandomHorizontalFlip(),
transforms.Resize((image_size, image_size)),
])
self.transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((image_size, image_size)),
])
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx]
target = self.targets[idx]
image = Image.fromarray(image.astype('uint8'))
if self.mode == 'train':
image = self.transform_train(image)
else:
image = self.transform_test(image)
return image, target
Hyper-parameters
# HyperParameters
SEED = 123
dataset = 'C10'
imratio = 0.1
BATCH_SIZE = 128
total_epochs = 100
decay_epochs=[int(total_epochs*0.5), int(total_epochs*0.75)]
margin = 1.0
lr = 0.1
#lr0 = 0.1 # (default: lr0=lr unless you specify the value and pass it to optimizer)
epoch_decay = 2e-3
weight_decay = 1e-4
beta0 = 0.9 # e.g., [0.999, 0.99, 0.9]
beta1 = 0.9 # e.g., [0.999, 0.99, 0.9]
sampling_rate = 0.2
Loading datasets
if dataset == 'C10':
IMG_SIZE = 32
train_data, train_targets = CIFAR10(root='./data', train=True).as_array()
test_data, test_targets = CIFAR10(root='./data', train=False).as_array()
elif dataset == 'C100':
IMG_SIZE = 32
train_data, train_targets = CIFAR100(root='./data', train=True).as_array()
test_data, test_targets = CIFAR100(root='./data', train=False).as_array()
elif dataset == 'STL10':
BATCH_SIZE = 32
IMG_SIZE = 96
train_data, train_targets = STL10(root='./data/', split='train')
test_data, test_targets = STL10(root='./data/', split='test')
elif dataset == 'C2':
IMG_SIZE = 50
train_data, train_targets = CAT_VS_DOG('./data/', train=True)
test_data, test_targets = CAT_VS_DOG('./data/', train=False)
(train_images, train_labels) = ImbalancedDataGenerator(verbose=True, random_seed=0).transform(train_data, train_targets, imratio=imratio)
(test_images, test_labels) = ImbalancedDataGenerator(verbose=True, random_seed=0).transform(test_data, test_targets, imratio=0.5)
trainSet = ImageDataset(train_images, train_labels, image_size=IMG_SIZE, crop_size=IMG_SIZE-2)
trainSet_eval = ImageDataset(train_images, train_labels, image_size=IMG_SIZE, crop_size=IMG_SIZE-2, mode='test')
testSet = ImageDataset(test_images, test_labels, image_size=IMG_SIZE, crop_size=IMG_SIZE-2, mode='test')
# parameters for sampler
sampler = DualSampler(trainSet, batch_size=BATCH_SIZE, sampling_rate=sampling_rate)
trainloader = torch.utils.data.DataLoader(trainSet, batch_size=BATCH_SIZE, sampler=sampler, shuffle=False, num_workers=2)
trainloader_eval = torch.utils.data.DataLoader(trainSet_eval, batch_size=BATCH_SIZE, shuffle=False, num_workers=2)
testloader = torch.utils.data.DataLoader(testSet, batch_size=BATCH_SIZE, shuffle=False, num_workers=2)
Model, Loss & Optimizer
Before training, we need to define model, loss function, optimizer.
set_all_seeds(123)
model = ResNet20(pretrained=False, last_activation=None, activations='relu', num_classes=1)
model = model.cuda()
# Compositional Training
loss_fn = CompositionalAUCLoss(k=1) # k is the number of inner updates for optimizing cross-entropy loss
optimizer = PDSCA(model.parameters(),
loss_fn=loss_fn,
lr=lr,
beta1=beta0,
beta2=beta1,
margin=margin,
epoch_decay=epoch_decay,
weight_decay=weight_decay)
Training
Now it’s time for training
print ('Start Training')
print ('-'*30)
train_log = []
test_log = []
for epoch in range(total_epochs):
if epoch in decay_epochs:
optimizer.update_regularizer(decay_factor=10, decay_factor0=10) # decrease learning rate by 10x & update regularizer
train_loss = []
model.train()
for data, targets in trainloader:
data, targets = data.cuda(), targets.cuda()
y_pred = model(data)
y_pred = torch.sigmoid(y_pred)
loss = loss_fn(y_pred, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
# evaluation on train & test sets
model.eval()
train_pred_list = []
train_true_list = []
for train_data, train_targets in trainloader_eval:
train_data = train_data.cuda()
train_pred = model(train_data)
train_pred_list.append(train_pred.cpu().detach().numpy())
train_true_list.append(train_targets.numpy())
train_true = np.concatenate(train_true_list)
train_pred = np.concatenate(train_pred_list)
train_auc = auc_roc_score(train_true, train_pred)
train_loss = np.mean(train_loss)
test_pred_list = []
test_true_list = []
for test_data, test_targets in testloader:
test_data = test_data.cuda()
test_pred = model(test_data)
test_pred_list.append(test_pred.cpu().detach().numpy())
test_true_list.append(test_targets.numpy())
test_true = np.concatenate(test_true_list)
test_pred = np.concatenate(test_pred_list)
val_auc = auc_roc_score(test_true, test_pred)
model.train()
# print results
print("epoch: %s, train_loss: %.4f, train_auc: %.4f, test_auc: %.4f, lr: %.4f"%(epoch, train_loss, train_auc, val_auc, optimizer.lr ))
train_log.append(train_auc)
test_log.append(val_auc)
Start Training
------------------------------
epoch: 0, train_loss: 0.3174, train_auc: 0.6830, test_auc: 0.6807, lr: 0.1000
epoch: 1, train_loss: 0.3001, train_auc: 0.6984, test_auc: 0.6836, lr: 0.1000
epoch: 2, train_loss: 0.2908, train_auc: 0.7305, test_auc: 0.7220, lr: 0.1000
epoch: 3, train_loss: 0.2835, train_auc: 0.7326, test_auc: 0.7179, lr: 0.1000
epoch: 4, train_loss: 0.2780, train_auc: 0.7555, test_auc: 0.7263, lr: 0.1000
epoch: 5, train_loss: 0.2695, train_auc: 0.7659, test_auc: 0.7469, lr: 0.1000
epoch: 6, train_loss: 0.2620, train_auc: 0.7897, test_auc: 0.7650, lr: 0.1000
epoch: 7, train_loss: 0.2557, train_auc: 0.8123, test_auc: 0.7800, lr: 0.1000
epoch: 8, train_loss: 0.2492, train_auc: 0.7633, test_auc: 0.7405, lr: 0.1000
epoch: 9, train_loss: 0.2438, train_auc: 0.8326, test_auc: 0.7915, lr: 0.1000
epoch: 10, train_loss: 0.2369, train_auc: 0.8218, test_auc: 0.7882, lr: 0.1000
epoch: 11, train_loss: 0.2305, train_auc: 0.8037, test_auc: 0.7679, lr: 0.1000
epoch: 12, train_loss: 0.2236, train_auc: 0.7826, test_auc: 0.7460, lr: 0.1000
epoch: 13, train_loss: 0.2213, train_auc: 0.8347, test_auc: 0.8093, lr: 0.1000
epoch: 14, train_loss: 0.2146, train_auc: 0.8534, test_auc: 0.8249, lr: 0.1000
epoch: 15, train_loss: 0.2103, train_auc: 0.8246, test_auc: 0.7876, lr: 0.1000
epoch: 16, train_loss: 0.2017, train_auc: 0.8833, test_auc: 0.8472, lr: 0.1000
epoch: 17, train_loss: 0.1962, train_auc: 0.8777, test_auc: 0.8444, lr: 0.1000
epoch: 18, train_loss: 0.1911, train_auc: 0.8821, test_auc: 0.8396, lr: 0.1000
epoch: 19, train_loss: 0.1884, train_auc: 0.8655, test_auc: 0.8297, lr: 0.1000
epoch: 20, train_loss: 0.1829, train_auc: 0.8416, test_auc: 0.8012, lr: 0.1000
epoch: 21, train_loss: 0.1782, train_auc: 0.8922, test_auc: 0.8488, lr: 0.1000
epoch: 22, train_loss: 0.1726, train_auc: 0.9077, test_auc: 0.8636, lr: 0.1000
epoch: 23, train_loss: 0.1690, train_auc: 0.8684, test_auc: 0.8314, lr: 0.1000
epoch: 24, train_loss: 0.1657, train_auc: 0.8866, test_auc: 0.8409, lr: 0.1000
epoch: 25, train_loss: 0.1622, train_auc: 0.8935, test_auc: 0.8524, lr: 0.1000
epoch: 26, train_loss: 0.1565, train_auc: 0.8968, test_auc: 0.8528, lr: 0.1000
epoch: 27, train_loss: 0.1571, train_auc: 0.9053, test_auc: 0.8601, lr: 0.1000
epoch: 28, train_loss: 0.1533, train_auc: 0.8878, test_auc: 0.8447, lr: 0.1000
epoch: 29, train_loss: 0.1513, train_auc: 0.9115, test_auc: 0.8746, lr: 0.1000
epoch: 30, train_loss: 0.1461, train_auc: 0.8959, test_auc: 0.8475, lr: 0.1000
epoch: 31, train_loss: 0.1459, train_auc: 0.9022, test_auc: 0.8597, lr: 0.1000
epoch: 32, train_loss: 0.1410, train_auc: 0.9262, test_auc: 0.8808, lr: 0.1000
epoch: 33, train_loss: 0.1416, train_auc: 0.9193, test_auc: 0.8815, lr: 0.1000
epoch: 34, train_loss: 0.1371, train_auc: 0.9350, test_auc: 0.8881, lr: 0.1000
epoch: 35, train_loss: 0.1374, train_auc: 0.9169, test_auc: 0.8662, lr: 0.1000
epoch: 36, train_loss: 0.1364, train_auc: 0.9253, test_auc: 0.8782, lr: 0.1000
epoch: 37, train_loss: 0.1333, train_auc: 0.9212, test_auc: 0.8767, lr: 0.1000
epoch: 38, train_loss: 0.1324, train_auc: 0.9092, test_auc: 0.8562, lr: 0.1000
epoch: 39, train_loss: 0.1313, train_auc: 0.9236, test_auc: 0.8721, lr: 0.1000
epoch: 40, train_loss: 0.1318, train_auc: 0.9306, test_auc: 0.8785, lr: 0.1000
epoch: 41, train_loss: 0.1296, train_auc: 0.8762, test_auc: 0.8228, lr: 0.1000
epoch: 42, train_loss: 0.1272, train_auc: 0.9129, test_auc: 0.8651, lr: 0.1000
epoch: 43, train_loss: 0.1266, train_auc: 0.9208, test_auc: 0.8657, lr: 0.1000
epoch: 44, train_loss: 0.1244, train_auc: 0.9350, test_auc: 0.8827, lr: 0.1000
epoch: 45, train_loss: 0.1223, train_auc: 0.9517, test_auc: 0.8962, lr: 0.1000
epoch: 46, train_loss: 0.1227, train_auc: 0.9395, test_auc: 0.8914, lr: 0.1000
epoch: 47, train_loss: 0.1181, train_auc: 0.9243, test_auc: 0.8730, lr: 0.1000
epoch: 48, train_loss: 0.1198, train_auc: 0.9596, test_auc: 0.9074, lr: 0.1000
epoch: 49, train_loss: 0.1169, train_auc: 0.9237, test_auc: 0.8730, lr: 0.1000
Reducing learning rate to 0.01000 @ T=12100!
Reducing learning rate (inner) to 0.01000 @ T=12100!
Updating regularizer @ T=12100!
epoch: 50, train_loss: 0.0836, train_auc: 0.9808, test_auc: 0.9267, lr: 0.0100
epoch: 51, train_loss: 0.0675, train_auc: 0.9848, test_auc: 0.9278, lr: 0.0100
epoch: 52, train_loss: 0.0605, train_auc: 0.9860, test_auc: 0.9279, lr: 0.0100
epoch: 53, train_loss: 0.0563, train_auc: 0.9881, test_auc: 0.9309, lr: 0.0100
epoch: 54, train_loss: 0.0511, train_auc: 0.9891, test_auc: 0.9299, lr: 0.0100
epoch: 55, train_loss: 0.0500, train_auc: 0.9895, test_auc: 0.9286, lr: 0.0100
epoch: 56, train_loss: 0.0469, train_auc: 0.9888, test_auc: 0.9243, lr: 0.0100
epoch: 57, train_loss: 0.0443, train_auc: 0.9914, test_auc: 0.9292, lr: 0.0100
epoch: 58, train_loss: 0.0417, train_auc: 0.9903, test_auc: 0.9227, lr: 0.0100
epoch: 59, train_loss: 0.0378, train_auc: 0.9911, test_auc: 0.9240, lr: 0.0100
epoch: 60, train_loss: 0.0395, train_auc: 0.9916, test_auc: 0.9251, lr: 0.0100
epoch: 61, train_loss: 0.0362, train_auc: 0.9914, test_auc: 0.9234, lr: 0.0100
epoch: 62, train_loss: 0.0359, train_auc: 0.9920, test_auc: 0.9232, lr: 0.0100
epoch: 63, train_loss: 0.0338, train_auc: 0.9938, test_auc: 0.9239, lr: 0.0100
epoch: 64, train_loss: 0.0311, train_auc: 0.9939, test_auc: 0.9260, lr: 0.0100
epoch: 65, train_loss: 0.0313, train_auc: 0.9933, test_auc: 0.9242, lr: 0.0100
epoch: 66, train_loss: 0.0284, train_auc: 0.9931, test_auc: 0.9194, lr: 0.0100
epoch: 67, train_loss: 0.0274, train_auc: 0.9946, test_auc: 0.9181, lr: 0.0100
epoch: 68, train_loss: 0.0269, train_auc: 0.9937, test_auc: 0.9192, lr: 0.0100
epoch: 69, train_loss: 0.0271, train_auc: 0.9952, test_auc: 0.9240, lr: 0.0100
epoch: 70, train_loss: 0.0232, train_auc: 0.9950, test_auc: 0.9245, lr: 0.0100
epoch: 71, train_loss: 0.0219, train_auc: 0.9929, test_auc: 0.9194, lr: 0.0100
epoch: 72, train_loss: 0.0228, train_auc: 0.9956, test_auc: 0.9214, lr: 0.0100
epoch: 73, train_loss: 0.0211, train_auc: 0.9956, test_auc: 0.9179, lr: 0.0100
epoch: 74, train_loss: 0.0194, train_auc: 0.9956, test_auc: 0.9214, lr: 0.0100
Reducing learning rate to 0.00100 @ T=18150!
Reducing learning rate (inner) to 0.00100 @ T=18150!
Updating regularizer @ T=18150!
epoch: 75, train_loss: 0.0175, train_auc: 0.9962, test_auc: 0.9209, lr: 0.0010
epoch: 76, train_loss: 0.0163, train_auc: 0.9964, test_auc: 0.9217, lr: 0.0010
epoch: 77, train_loss: 0.0174, train_auc: 0.9965, test_auc: 0.9200, lr: 0.0010
epoch: 78, train_loss: 0.0168, train_auc: 0.9966, test_auc: 0.9200, lr: 0.0010
epoch: 79, train_loss: 0.0160, train_auc: 0.9966, test_auc: 0.9201, lr: 0.0010
epoch: 80, train_loss: 0.0153, train_auc: 0.9966, test_auc: 0.9202, lr: 0.0010
epoch: 81, train_loss: 0.0152, train_auc: 0.9967, test_auc: 0.9197, lr: 0.0010
epoch: 82, train_loss: 0.0139, train_auc: 0.9966, test_auc: 0.9200, lr: 0.0010
epoch: 83, train_loss: 0.0157, train_auc: 0.9970, test_auc: 0.9200, lr: 0.0010
epoch: 84, train_loss: 0.0141, train_auc: 0.9969, test_auc: 0.9194, lr: 0.0010
epoch: 85, train_loss: 0.0144, train_auc: 0.9969, test_auc: 0.9205, lr: 0.0010
epoch: 86, train_loss: 0.0143, train_auc: 0.9970, test_auc: 0.9206, lr: 0.0010
epoch: 87, train_loss: 0.0144, train_auc: 0.9969, test_auc: 0.9196, lr: 0.0010
epoch: 88, train_loss: 0.0142, train_auc: 0.9969, test_auc: 0.9193, lr: 0.0010
epoch: 89, train_loss: 0.0139, train_auc: 0.9968, test_auc: 0.9191, lr: 0.0010
epoch: 90, train_loss: 0.0133, train_auc: 0.9969, test_auc: 0.9198, lr: 0.0010
epoch: 91, train_loss: 0.0138, train_auc: 0.9971, test_auc: 0.9202, lr: 0.0010
epoch: 92, train_loss: 0.0144, train_auc: 0.9971, test_auc: 0.9191, lr: 0.0010
epoch: 93, train_loss: 0.0125, train_auc: 0.9969, test_auc: 0.9194, lr: 0.0010
epoch: 94, train_loss: 0.0139, train_auc: 0.9970, test_auc: 0.9193, lr: 0.0010
epoch: 95, train_loss: 0.0131, train_auc: 0.9970, test_auc: 0.9187, lr: 0.0010
epoch: 96, train_loss: 0.0132, train_auc: 0.9969, test_auc: 0.9191, lr: 0.0010
epoch: 97, train_loss: 0.0136, train_auc: 0.9968, test_auc: 0.9173, lr: 0.0010
epoch: 98, train_loss: 0.0129, train_auc: 0.9970, test_auc: 0.9191, lr: 0.0010
epoch: 99, train_loss: 0.0129, train_auc: 0.9970, test_auc: 0.9194, lr: 0.0010
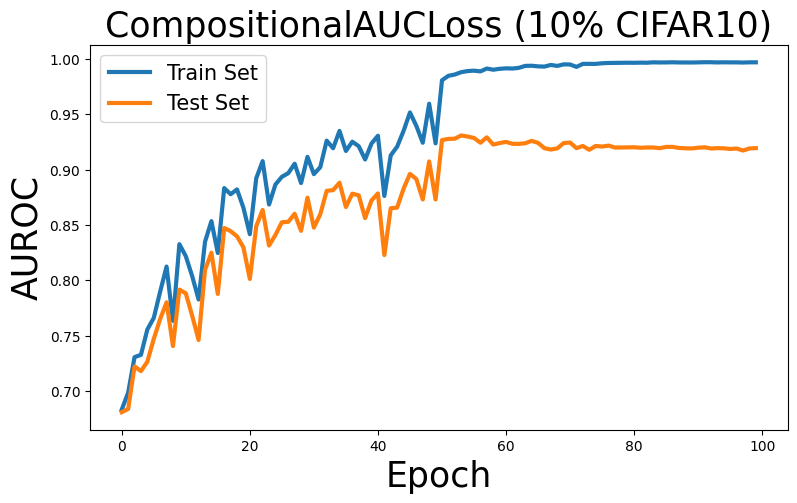
Visualization
Now, let’s see the learning curve for optimizing AUROC on train and test sets.
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (9,5)
x=np.arange(len(train_log))
plt.figure()
plt.plot(x, train_log, lineStyle='-', label='Train Set', linewidth=3)
plt.plot(x, test_log, lineStyle='-', label='Test Set', linewidth=3)
plt.title('CompositionalAUCLoss (10% CIFAR10)',fontsize=25)
plt.legend(fontsize=15)
plt.ylabel('AUROC', fontsize=25)
plt.xlabel('Epoch', fontsize=25)
Text(0.5, 0, 'Epoch')