Optimizing Global Contrastive Loss with SogCLR and Cosine Gamma Schedule
Author: Xiyuan Wei, Tianbao Yang
Introduction
In this tutorial, we compare the performance of SogCLR algorithm using cosine \(\gamma\) decay schedule and constant schedule in a typical bimodal contrastive learning task. Previous algorithms optimizing the Global Contrastive Loss family (e.g., SogCLR and iSogCLR) sets \(\gamma\) to a constant. In this tutorial, we compare the constant schedule with a cosine decay schedule: let \(e\) be the current epoch, \(E\) be the number of decay epochs and \(\gamma_{\mathrm{min}}\) be the final value, then the value of \(\gamma\) at this epoch is given by
Here \(E\) is not necessarily equal to the number of training epochs, we recommend to set it to half of the number of training epochs. If \(e> E\), then \(\gamma\) is set to \(\gamma_{\mathrm{min}}\).
In pretraining stage, we use a subset of the CC3M dataset, which contains about 300,000 image-text pairs. And then we evaluate the pretrained models via zero-shot image/text retrieval on MS-COCO dataset. We provide the metadata of the training subset and evluation set here. This tutorial is forked from the iSogCLR tutorial.
The experiment in this tutorial is conducted one 4 Nvidia A30 GPUs, you can modify the CUDA_VISIBLE_DEVICES option and batch_size_train option based on your equipments.
Reference
If you find this tutorial helpful in your work, please cite our library paper.
Importing required libs
!pip install -U libauc
!pip install timm
!pip install transformers
import os
os.environ["TOKENIZERS_PARALLELISM"] = "true"
os.environ["CUDA_VISIBLE_DEVICES"] = '6,7,8,9' # distributed training: '0,1,2,3'
import re
import argparse
from pathlib import Path
import json
import os
import random
import math
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
from torch import optim
import torchvision
from torchvision import transforms
from torch.utils.data import Dataset, Subset, DataLoader
from PIL import Image
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
Image.MAX_IMAGE_PIXELS = None
import cv2
import numpy as np
import timm
from transformers import AutoModel, AutoTokenizer
import libauc
from libauc.losses.contrastive import GCLoss_v2
from libauc.optimizers import SogCLR
from libauc.utils.paper_utils import CosineLRScheduler
Arguments for experiments
# path to data folder
data_path = './datasets/cc3m'
train_file = 'cc3m_subset_new.json'
# model config
image_encoder = 'resnet50'
text_encoder = 'distilbert-base-uncased'
image_res = 256
vision_width = 768
embed_dim = 256
seed = 42
# optimizer and schedular
opt = 'adamW'
lr = 3e-4
min_lr = 1e-5
warmup = True
warmup_lr = 1e-5
weight_decay = 0.02
decay_rate = 1
epochs = 30
warmup_epochs = 20
cooldown_epochs = 0
# training & test settings
batch_size_train = 256
batch_size_test = 512
k_test = 256
# output path
output_dir = './output/'
# AMP training
use_amp = True
# loss config
temp = 0.01 # the temperature parameter for clip or sogclr
n_gpus = torch.cuda.device_count()
val_coco_file = 'coco_val_new.json'
test_coco_file = 'coco_test_new.json'
coco_image_root = './datasets/coco'
Path(output_dir).mkdir(parents=True, exist_ok=True)
Define helper functions
# we employ this function to preprocess the captions
def pre_caption(caption, max_words):
caption = re.sub(
r"([,.'!?\"()*#:;~])",
'',
caption.lower(),
).replace('-', ' ').replace('/', ' ').replace('<person>', 'person')
caption = re.sub(
r"\s{2,}",
' ',
caption,
)
caption = caption.rstrip('\n')
caption = caption.strip(' ')
#truncate caption
caption_words = caption.split(' ')
if len(caption_words)>max_words:
caption = ' '.join(caption_words[:max_words])
return caption
class train_set(Dataset):
def __init__(self, ann_file, transform, image_root, max_words=30):
self.ann = []
for f in ann_file:
self.ann += json.load(open(f,'r'))
self.transform = transform
self.image_root = image_root
self.max_words = max_words
self.img_ids = {}
n = 0
for ann in self.ann:
img_id = ann['image_id']
if img_id not in self.img_ids.keys():
self.img_ids[img_id] = n
n += 1
def __len__(self):
return len(self.ann)
def __getitem__(self, index):
ann = self.ann[index]
# image_path = os.path.join(self.image_root, ann['image'])
image_path = ann['image']
image = Image.open(image_path).convert('RGB')
image = self.transform(image)
caption = pre_caption(ann['caption'], self.max_words)
return image, caption, self.img_ids[ann['image_id']], index
class eval_set(Dataset):
def __init__(self, ann_file, transform, image_root, max_words=30):
self.ann = json.load(open(ann_file,'r'))
self.transform = transform
self.image_root = image_root
self.max_words = max_words
self.text = []
self.image = []
self.txt2img = {}
self.img2txt = {}
txt_id = 0
for img_id, ann in enumerate(self.ann):
self.image.append(ann['image'])
self.img2txt[img_id] = []
# 'val2014/000000184613.jpg'
image_path = os.path.join(self.image_root, ann['image'].split('/')[0], f"COCO_val2014_{ann['image'].split('/')[-1]}")
ann['image'] = image_path
for i, caption in enumerate(ann['caption']):
self.text.append(pre_caption(caption,self.max_words))
self.img2txt[img_id].append(txt_id)
self.txt2img[txt_id] = img_id
txt_id += 1
def __len__(self):
return len(self.image)
def __getitem__(self, index):
image_path = self.ann[index]['image']
image = Image.open(image_path).convert('RGB')
image = self.transform(image)
return image, index
def add_weight_decay(model, weight_decay=1e-5, skip_list=()):
decay = []
no_decay = []
for name, param in model.named_parameters():
if not param.requires_grad:
continue # frozen weights
if len(param.shape) == 1 or name.endswith(".bias") or name in skip_list:
no_decay.append(param)
else:
decay.append(param)
return [
{'params': no_decay, 'weight_decay': 0.},
{'params': decay, 'weight_decay': weight_decay}]
def create_optimizer(model, opt, weight_decay=1e-5, filter_bias_and_bn=True):
if weight_decay and filter_bias_and_bn:
skip = {}
if hasattr(model, 'no_weight_decay'):
skip = model.no_weight_decay()
parameters = add_weight_decay(model, weight_decay, skip)
weight_decay = 0.
else:
parameters = model.parameters()
opt_args = dict(lr=lr, weight_decay=weight_decay)
optimizer = SogCLR(parameters, mode=opt, **opt_args)
return optimizer
def create_scheduler(optimizer):
num_epochs = epochs
lr_scheduler = CosineLRScheduler(
optimizer,
t_initial = num_epochs,
t_mul = 1.0,
lr_min = min_lr,
decay_rate = decay_rate,
warmup_lr_init = warmup_lr,
warmup_t = warmup_epochs,
cycle_limit = 1,
t_in_epochs = True,
noise_range_t = None,
noise_pct = 0.67,
noise_std = 1.0,
noise_seed = 42,
)
return lr_scheduler
Reproducibility
The following functions limit the number of sources of randomness behaviors, such as model intialization, data shuffling, etcs.
# fix the seed for reproducibility
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
cudnn.benchmark = True
Building the model
# The following class includes the image encoder, text encoder and several objectives
class Model(nn.Module):
def __init__(self, image_encoder = None, text_encoder = None,
embed_dim = 256, init_model = True, bsz = 128,
gamma = 0.9, # the coefficient for moving average estimator
temp = 0.01, # temperature for clip or sogclr
gamma_schedule = 'cosine',
gamma_decay_epochs = 1,
):
super().__init__()
self.temp = temp
self.visual_encoder = timm.create_model(image_encoder, pretrained=init_model)
self.visual_encoder.reset_classifier(0)
self.text_encoder = AutoModel.from_pretrained(text_encoder, local_files_only=False)
if not init_model:
self.text_encoder.init_weights()
self.vision_proj = nn.Linear(self.visual_encoder.num_features, embed_dim)
self.text_proj = nn.Linear(768, embed_dim)
self.criterion = GCLoss_v2(tau=temp, gamma=gamma, enable_isogclr=False,
gamma_schedule=gamma_schedule, gamma_decay_epochs=gamma_decay_epochs)
def forward(self, image, text_ids, text_att_masks, idx, text_idx, epoch):
image_embeds = self.visual_encoder(image)
image_embeds = self.vision_proj(image_embeds)
image_feat = F.normalize(image_embeds, dim=-1)
text_output = self.text_encoder(text_ids, attention_mask=text_att_masks, output_hidden_states=False)
text_embeds = self.text_proj(text_output.last_hidden_state[:,0,:])
text_feat = F.normalize(text_embeds, dim=-1)
loss, info = self.criterion(image_feat, text_feat, idx)
return loss, info
Training functions
print_freq = 50 # user can determine how many iterations to output (e.g., 50 by default)
def epoch_train(model, data_loader, optimizer, tokenizer, epoch, max_epoch, warmup_steps, device, scheduler, grad_scaler):
# train
model.train()
step_size = 100
warmup_iterations = warmup_steps * step_size
if hasattr(model, 'module'):
model_orig = model.module
else:
model_orig = model
# adjust gamma based on gamma schedule
if hasattr(model_orig.criterion, 'adjust_gamma'):
model_orig.criterion.adjust_gamma(epoch)
for i,(image, text, idx, text_idx) in enumerate(data_loader):
optimizer.zero_grad()
image = image.to(device, non_blocking=True)
idx = idx.to(device, non_blocking=True)
text_idx = text_idx.to(device, non_blocking=True)
text_input = tokenizer(text, padding='max_length', truncation=True, max_length=30, return_tensors="pt").to(device)
if grad_scaler is None:
loss, info = model(image, text_input.input_ids, text_input.attention_mask, idx=idx, text_idx=text_idx, epoch=epoch)
loss.mean().backward()
optimizer.step()
else:
with torch.cuda.amp.autocast():
loss, info = model(image, text_input.input_ids, text_input.attention_mask, idx=idx, text_idx=text_idx, epoch=epoch)
grad_scaler.scale(loss.mean()).backward()
grad_scaler.step(optimizer)
grad_scaler.update()
if epoch==0 and i%step_size==0 and i<=warmup_iterations:
scheduler.step(i//step_size)
if i%print_freq == 0:
lr = optimizer.param_groups[0]["lr"]
print("Epoch:", epoch, "iteration:", i, "lr:", lr, "loss:", loss.mean().item())
if info is not None:
print("tau_img: %.4f, tau_txt: %.4f" % (info[0].mean(), info[1].mean()))
Evaluation functions
@torch.no_grad()
def evaluation(model, data_loader, tokenizer, device):
# test
model.eval()
print('Computing features for evaluation...')
texts = data_loader.dataset.text
num_text = len(texts)
text_bs = 256
text_embeds = []
for i in range(0, num_text, text_bs):
text = texts[i: min(num_text, i+text_bs)]
text_input = tokenizer(text, padding='max_length', truncation=True, max_length=30, return_tensors="pt").to(device)
text_output = model.text_encoder(text_input.input_ids, attention_mask=text_input.attention_mask, output_hidden_states=False)
text_embed = F.normalize(model.text_proj(text_output.last_hidden_state[:,0,:]), dim=-1)
text_embeds.append(text_embed)
text_embeds = torch.cat(text_embeds,dim=0)
image_embeds = []
for image, img_id in data_loader:
image = image.to(device)
image_feat = model.visual_encoder(image)
image_embed = model.vision_proj(image_feat)
image_embed = F.normalize(image_embed, dim=-1)
image_embeds.append(image_embed)
image_embeds = torch.cat(image_embeds,dim=0)
sims_matrix = image_embeds @ text_embeds.t()
score_matrix_i2t = torch.full((len(data_loader.dataset.image),len(texts)),-100.0).to(device)
for i,sims in enumerate(sims_matrix):
topk_sim, topk_idx = sims.topk(k=k_test, dim=0)
score_matrix_i2t[i, topk_idx] = topk_sim
sims_matrix = sims_matrix.t()
score_matrix_t2i = torch.full((len(texts),len(data_loader.dataset.image)),-100.0).to(device)
for i,sims in enumerate(sims_matrix):
topk_sim, topk_idx = sims.topk(k=k_test, dim=0)
score_matrix_t2i[i, topk_idx] = topk_sim
return score_matrix_i2t.cpu().numpy(), score_matrix_t2i.cpu().numpy()
@torch.no_grad()
def itm_eval(scores_i2t, scores_t2i, txt2img, img2txt):
#Images->Text
ranks = np.zeros(scores_i2t.shape[0])
for index,score in enumerate(scores_i2t):
inds = np.argsort(score)[::-1]
# Score
rank = 1e20
for i in img2txt[index]:
tmp = np.where(inds == i)[0][0]
if tmp < rank:
rank = tmp
ranks[index] = rank
# Compute metrics
tr1 = 100.0 * len(np.where(ranks < 1)[0]) / len(ranks)
tr5 = 100.0 * len(np.where(ranks < 5)[0]) / len(ranks)
tr10 = 100.0 * len(np.where(ranks < 10)[0]) / len(ranks)
#Text->Images
ranks = np.zeros(scores_t2i.shape[0])
for index,score in enumerate(scores_t2i):
inds = np.argsort(score)[::-1]
ranks[index] = np.where(inds == txt2img[index])[0][0]
# Compute metrics
ir1 = 100.0 * len(np.where(ranks < 1)[0]) / len(ranks)
ir5 = 100.0 * len(np.where(ranks < 5)[0]) / len(ranks)
ir10 = 100.0 * len(np.where(ranks < 10)[0]) / len(ranks)
tr_mean = (tr1 + tr5 + tr10) / 3
ir_mean = (ir1 + ir5 + ir10) / 3
r_mean = (tr_mean + ir_mean) / 2
eval_result = {'txt_r1': tr1,
'txt_r5': tr5,
'txt_r10': tr10,
'txt_r_mean': tr_mean,
'img_r1': ir1,
'img_r5': ir5,
'img_r10': ir10,
'img_r_mean': ir_mean,
'r_mean': r_mean}
return eval_result
Dataset Pipeline for Bimodal Contrastive Learning
# set up the transformation, datasets and dataloaders
train_transform = transforms.Compose([
transforms.RandomResizedCrop(image_res, scale=(0.5, 1.0), interpolation=Image.BICUBIC),
transforms.RandomHorizontalFlip(),
transforms.RandAugment(),
transforms.ToTensor(),
transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
])
test_transform = transforms.Compose([
transforms.Resize((image_res, image_res), interpolation=Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
])
train_dataset = train_set([train_file], train_transform, data_path)
val_coco_dataset = eval_set(val_coco_file, test_transform, coco_image_root)
test_coco_dataset = eval_set(test_coco_file, test_transform, coco_image_root)
print("len of train_dataset:", len(train_dataset))
print("len of coco val/test:", len(val_coco_dataset), len(test_coco_dataset))
train_loader = DataLoader(train_dataset, batch_size=batch_size_train * n_gpus, num_workers=16, pin_memory=True,
shuffle=True, drop_last=True, prefetch_factor=4)
val_loader = DataLoader(val_coco_dataset, batch_size=batch_size_test, num_workers=16, pin_memory=True,
shuffle=False, drop_last=False, prefetch_factor=12)
test_loader = DataLoader(test_coco_dataset, batch_size=batch_size_test, num_workers=16, pin_memory=True,
shuffle=False, drop_last=False, prefetch_factor=12)
Pretraining and evaluation for SogCLR with Cosine Gamma
For consine gamma schedule, we recommend setting gamma_decay_epochs to 50% of the number of training epochs.
gamma = 0.2 # the parameter for the moving average estimator in sogclr/isogclr
gamma_schedule = "cosine"
gamma_decay_epochs = epochs // 2
# create the model and wrap it in DDP
tokenizer = AutoTokenizer.from_pretrained(text_encoder, local_files_only=False)
model = Model(image_encoder=image_encoder, text_encoder=text_encoder, embed_dim=embed_dim,
init_model=True, bsz=batch_size_train, gamma=gamma, temp=temp,
gamma_schedule=gamma_schedule, gamma_decay_epochs=gamma_decay_epochs)
model = model.cuda()
if n_gpus > 1:
print("Using", n_gpus, "GPUs")
model = nn.DataParallel(model)
# set up the optimizer and objective function
optimizer = create_optimizer(model, opt, weight_decay)
lr_scheduler = create_scheduler(optimizer)
if use_amp:
grad_scaler = torch.cuda.amp.GradScaler()
else:
grad_scaler = None
# training loop
for epoch in range(0, epochs):
train_stats = epoch_train(model, train_loader, optimizer, tokenizer, epoch, epochs,
warmup_epochs, torch.device('cuda'), lr_scheduler, grad_scaler)
# evaluate the model on ms-coco data
try:
score_val_i2t_coco, score_val_t2i_coco = evaluation(model.module, val_loader, tokenizer, torch.device('cuda'))
score_test_i2t_coco, score_test_t2i_coco = evaluation(model.module, test_loader, tokenizer, torch.device('cuda'))
except:
# for non-distributed training
score_val_i2t_coco, score_val_t2i_coco = evaluation(model, val_loader, tokenizer, torch.device('cuda'))
score_test_i2t_coco, score_test_t2i_coco = evaluation(model, test_loader, tokenizer, torch.device('cuda'))
print("Epoch:", epoch)
val_result_coco = itm_eval(score_val_i2t_coco, score_val_t2i_coco, val_loader.dataset.txt2img, val_loader.dataset.img2txt)
print("coco val:", val_result_coco)
test_result_coco = itm_eval(score_test_i2t_coco, score_test_t2i_coco, test_loader.dataset.txt2img, test_loader.dataset.img2txt)
print("coco test:", test_result_coco)
lr_scheduler.step(epoch+warmup_epochs+1)
Epoch: 0, gamma: 1.000
Epoch: 0 iteration: 0 lr: 1e-05 loss: 25.562393188476562
Epoch: 0 iteration: 50 lr: 1e-05 loss: 7.046422958374023
Epoch: 0 iteration: 100 lr: 2.45e-05 loss: 4.479846000671387
Epoch: 0 iteration: 150 lr: 2.45e-05 loss: 1.4941186904907227
Epoch: 0 iteration: 200 lr: 3.899999999999999e-05 loss: 0.7526077032089233
Epoch: 0 iteration: 250 lr: 3.899999999999999e-05 loss: 0.5853667259216309
Computing features for evaluation...
Computing features for evaluation...
Epoch: 0
coco val: {'txt_r1': 3.32, 'txt_r5': 11.82, 'txt_r10': 18.46, 'txt_r_mean': 11.200000000000001, 'img_r1': 1.5953618552578968, 'img_r5': 6.261495401839264, 'img_r10': 10.547780887644942, 'img_r_mean': 6.1348793815807, 'r_mean': 8.667439690790351}
coco test: {'txt_r1': 3.18, 'txt_r5': 11.2, 'txt_r10': 17.26, 'txt_r_mean': 10.546666666666667, 'img_r1': 1.6113554578168732, 'img_r5': 6.1975209916033585, 'img_r10': 10.735705717712914, 'img_r_mean': 6.1815273890443825, 'r_mean': 8.364097027855525}
Epoch: 1, gamma: 0.991
Epoch: 1 iteration: 0 lr: 0.0002992056748283996 loss: 0.6412824392318726
Epoch: 1 iteration: 50 lr: 0.0002992056748283996 loss: 0.08212701976299286
Epoch: 1 iteration: 100 lr: 0.0002992056748283996 loss: 0.32320332527160645
Epoch: 1 iteration: 150 lr: 0.0002992056748283996 loss: 0.1429944634437561
Epoch: 1 iteration: 200 lr: 0.0002992056748283996 loss: -0.14057549834251404
Epoch: 1 iteration: 250 lr: 0.0002992056748283996 loss: 0.45640790462493896
Computing features for evaluation...
Computing features for evaluation...
Epoch: 1
coco val: {'txt_r1': 13.88, 'txt_r5': 33.96, 'txt_r10': 45.62, 'txt_r_mean': 31.153333333333336, 'img_r1': 7.7329068372650935, 'img_r5': 22.159136345461814, 'img_r10': 32.70291883246701, 'img_r_mean': 20.864987338397974, 'r_mean': 26.009160335865655}
coco test: {'txt_r1': 13.38, 'txt_r5': 32.54, 'txt_r10': 43.6, 'txt_r_mean': 29.840000000000003, 'img_r1': 7.888844462215114, 'img_r5': 22.423030787684926, 'img_r10': 33.406637345061974, 'img_r_mean': 21.23950419832067, 'r_mean': 25.53975209916034}
Epoch: 2, gamma: 0.965
Epoch: 2 iteration: 0 lr: 0.0002968314021064018 loss: -0.9379413723945618
Epoch: 2 iteration: 50 lr: 0.0002968314021064018 loss: 0.14994144439697266
Epoch: 2 iteration: 100 lr: 0.0002968314021064018 loss: 0.48201847076416016
Epoch: 2 iteration: 150 lr: 0.0002968314021064018 loss: -0.006118714809417725
Epoch: 2 iteration: 200 lr: 0.0002968314021064018 loss: 0.0514066182076931
Epoch: 2 iteration: 250 lr: 0.0002968314021064018 loss: 0.3719228208065033
Computing features for evaluation...
Computing features for evaluation...
Epoch: 2
coco val: {'txt_r1': 16.14, 'txt_r5': 37.82, 'txt_r10': 49.62, 'txt_r_mean': 34.526666666666664, 'img_r1': 9.776089564174331, 'img_r5': 26.90923630547781, 'img_r10': 38.16473410635746, 'img_r_mean': 24.950019992003195, 'r_mean': 29.73834332933493}
coco test: {'txt_r1': 17.14, 'txt_r5': 36.9, 'txt_r10': 48.7, 'txt_r_mean': 34.24666666666667, 'img_r1': 10.111955217912834, 'img_r5': 27.109156337465013, 'img_r10': 38.456617353058775, 'img_r_mean': 25.22590963614554, 'r_mean': 29.736288151406107}
Epoch: 3, gamma: 0.924
Epoch: 3 iteration: 0 lr: 0.00029290319486279724 loss: -1.0872976779937744
Epoch: 3 iteration: 50 lr: 0.00029290319486279724 loss: 0.2618948221206665
Epoch: 3 iteration: 100 lr: 0.00029290319486279724 loss: 0.2907547950744629
Epoch: 3 iteration: 150 lr: 0.00029290319486279724 loss: -0.04956810176372528
Epoch: 3 iteration: 200 lr: 0.00029290319486279724 loss: -0.21110652387142181
Epoch: 3 iteration: 250 lr: 0.00029290319486279724 loss: 0.48659956455230713
Computing features for evaluation...
Computing features for evaluation...
Epoch: 3
coco val: {'txt_r1': 16.88, 'txt_r5': 36.98, 'txt_r10': 49.62, 'txt_r_mean': 34.49333333333333, 'img_r1': 10.60375849660136, 'img_r5': 27.844862055177927, 'img_r10': 39.11235505797681, 'img_r_mean': 25.853658536585368, 'r_mean': 30.173495934959348}
coco test: {'txt_r1': 16.88, 'txt_r5': 37.52, 'txt_r10': 49.3, 'txt_r_mean': 34.56666666666667, 'img_r1': 10.79968012794882, 'img_r5': 28.008796481407437, 'img_r10': 39.58416633346661, 'img_r_mean': 26.130880980940958, 'r_mean': 30.348773823803814}
Epoch: 4, gamma: 0.868
Epoch: 4 iteration: 0 lr: 0.00028746409135817707 loss: -1.1554466485977173
Epoch: 4 iteration: 50 lr: 0.00028746409135817707 loss: 0.30480873584747314
Epoch: 4 iteration: 100 lr: 0.00028746409135817707 loss: 0.33791103959083557
Epoch: 4 iteration: 150 lr: 0.00028746409135817707 loss: 0.08627769351005554
Epoch: 4 iteration: 200 lr: 0.00028746409135817707 loss: 0.2642784118652344
Epoch: 4 iteration: 250 lr: 0.00028746409135817707 loss: 0.07905745506286621
Computing features for evaluation...
Computing features for evaluation...
Epoch: 4
coco val: {'txt_r1': 16.8, 'txt_r5': 38.8, 'txt_r10': 51.18, 'txt_r_mean': 35.593333333333334, 'img_r1': 11.38344662135146, 'img_r5': 29.196321471411437, 'img_r10': 41.21951219512195, 'img_r_mean': 27.26642676262828, 'r_mean': 31.42988004798081}
coco test: {'txt_r1': 17.4, 'txt_r5': 38.14, 'txt_r10': 49.8, 'txt_r_mean': 35.11333333333334, 'img_r1': 11.303478608556578, 'img_r5': 29.524190323870453, 'img_r10': 41.50739704118352, 'img_r_mean': 27.445021991203518, 'r_mean': 31.279177662268427}
Epoch: 5, gamma: 0.800
Epoch: 5 iteration: 0 lr: 0.0002805736835487436 loss: -0.8010793924331665
Epoch: 5 iteration: 50 lr: 0.0002805736835487436 loss: -0.04104653745889664
Epoch: 5 iteration: 100 lr: 0.0002805736835487436 loss: -0.05042795091867447
Epoch: 5 iteration: 150 lr: 0.0002805736835487436 loss: 0.3482283651828766
Epoch: 5 iteration: 200 lr: 0.0002805736835487436 loss: -0.19366544485092163
Epoch: 5 iteration: 250 lr: 0.0002805736835487436 loss: 0.18530279397964478
Computing features for evaluation...
Computing features for evaluation...
Epoch: 5
coco val: {'txt_r1': 17.92, 'txt_r5': 38.94, 'txt_r10': 50.88, 'txt_r_mean': 35.913333333333334, 'img_r1': 11.76329468212715, 'img_r5': 30.32387045181927, 'img_r10': 42.21911235505798, 'img_r_mean': 28.1020924963348, 'r_mean': 32.007712914834066}
coco test: {'txt_r1': 17.56, 'txt_r5': 38.92, 'txt_r10': 51.08, 'txt_r_mean': 35.85333333333333, 'img_r1': 11.451419432227109, 'img_r5': 29.976009596161536, 'img_r10': 41.73530587764894, 'img_r_mean': 27.72091163534586, 'r_mean': 31.787122484339598}
Epoch: 6, gamma: 0.724
Epoch: 6 iteration: 0 lr: 0.0002723074641843674 loss: -0.79267418384552
Epoch: 6 iteration: 50 lr: 0.0002723074641843674 loss: 0.18923521041870117
Epoch: 6 iteration: 100 lr: 0.0002723074641843674 loss: 0.20457345247268677
Epoch: 6 iteration: 150 lr: 0.0002723074641843674 loss: 0.4892052114009857
Epoch: 6 iteration: 200 lr: 0.0002723074641843674 loss: 0.04444585740566254
Epoch: 6 iteration: 250 lr: 0.0002723074641843674 loss: 0.47790783643722534
Computing features for evaluation...
Computing features for evaluation...
Epoch: 6
coco val: {'txt_r1': 17.84, 'txt_r5': 39.14, 'txt_r10': 51.14, 'txt_r_mean': 36.04, 'img_r1': 12.019192323070772, 'img_r5': 30.059976009596163, 'img_r10': 42.215113954418236, 'img_r_mean': 28.098094095695057, 'r_mean': 32.069047047847526}
coco test: {'txt_r1': 16.96, 'txt_r5': 38.64, 'txt_r10': 50.88, 'txt_r_mean': 35.49333333333333, 'img_r1': 11.91923230707717, 'img_r5': 30.631747301079567, 'img_r10': 42.19512195121951, 'img_r_mean': 28.248700519792084, 'r_mean': 31.87101692656271}
Epoch: 7, gamma: 0.642
Epoch: 7 iteration: 0 lr: 0.00026275599969422214 loss: -0.6361552476882935
Epoch: 7 iteration: 50 lr: 0.00026275599969422214 loss: 0.06120859831571579
Epoch: 7 iteration: 100 lr: 0.00026275599969422214 loss: -0.07773126661777496
Epoch: 7 iteration: 150 lr: 0.00026275599969422214 loss: 0.44026297330856323
Epoch: 7 iteration: 200 lr: 0.00026275599969422214 loss: 0.20525489747524261
Epoch: 7 iteration: 250 lr: 0.00026275599969422214 loss: 0.4531901776790619
Computing features for evaluation...
Computing features for evaluation...
Epoch: 7
coco val: {'txt_r1': 17.0, 'txt_r5': 37.82, 'txt_r10': 48.92, 'txt_r_mean': 34.580000000000005, 'img_r1': 12.307077169132347, 'img_r5': 30.60375849660136, 'img_r10': 42.27109156337465, 'img_r_mean': 28.39397574303612, 'r_mean': 31.48698787151806}
coco test: {'txt_r1': 16.14, 'txt_r5': 36.86, 'txt_r10': 48.22, 'txt_r_mean': 33.74, 'img_r1': 12.103158736505398, 'img_r5': 30.647740903638546, 'img_r10': 42.43102758896441, 'img_r_mean': 28.39397574303612, 'r_mean': 31.06698787151806}
Epoch: 8, gamma: 0.558
Epoch: 8 iteration: 0 lr: 0.0002520239379220344 loss: -0.3692495822906494
Epoch: 8 iteration: 50 lr: 0.0002520239379220344 loss: 0.002105802297592163
Epoch: 8 iteration: 100 lr: 0.0002520239379220344 loss: 0.40007448196411133
Epoch: 8 iteration: 150 lr: 0.0002520239379220344 loss: -0.1796630322933197
Epoch: 8 iteration: 200 lr: 0.0002520239379220344 loss: 0.013615682721138
Epoch: 8 iteration: 250 lr: 0.0002520239379220344 loss: 0.08308104425668716
Computing features for evaluation...
Computing features for evaluation...
Epoch: 8
coco val: {'txt_r1': 18.38, 'txt_r5': 40.12, 'txt_r10': 52.72, 'txt_r_mean': 37.07333333333333, 'img_r1': 11.93922431027589, 'img_r5': 30.519792083166735, 'img_r10': 42.147141143542584, 'img_r_mean': 28.202052512328404, 'r_mean': 32.637692922830865}
coco test: {'txt_r1': 18.12, 'txt_r5': 40.16, 'txt_r10': 52.06, 'txt_r_mean': 36.78, 'img_r1': 12.17512994802079, 'img_r5': 30.483806477409036, 'img_r10': 42.02319072371051, 'img_r_mean': 28.227375716380113, 'r_mean': 32.503687858190055}
Epoch: 9, gamma: 0.476
Epoch: 9 iteration: 0 lr: 0.00024022886158240857 loss: -0.08598324656486511
Epoch: 9 iteration: 50 lr: 0.00024022886158240857 loss: 0.003968283534049988
Epoch: 9 iteration: 100 lr: 0.00024022886158240857 loss: -0.21741534769535065
Epoch: 9 iteration: 150 lr: 0.00024022886158240857 loss: 0.05582163855433464
Epoch: 9 iteration: 200 lr: 0.00024022886158240857 loss: 0.24776872992515564
Epoch: 9 iteration: 250 lr: 0.00024022886158240857 loss: -0.3975985646247864
Computing features for evaluation...
Computing features for evaluation...
Epoch: 9
coco val: {'txt_r1': 18.54, 'txt_r5': 39.6, 'txt_r10': 52.06, 'txt_r_mean': 36.733333333333334, 'img_r1': 12.451019592163135, 'img_r5': 31.307477009196322, 'img_r10': 43.03078768492603, 'img_r_mean': 28.929761428761832, 'r_mean': 32.831547381047585}
coco test: {'txt_r1': 17.12, 'txt_r5': 39.16, 'txt_r10': 50.48, 'txt_r_mean': 35.586666666666666, 'img_r1': 12.642942822870852, 'img_r5': 31.311475409836067, 'img_r10': 42.93082766893243, 'img_r_mean': 28.961748633879782, 'r_mean': 32.274207650273226}
Epoch: 10, gamma: 0.400
Epoch: 10 iteration: 0 lr: 0.00022749999999999997 loss: -0.6577126979827881
Epoch: 10 iteration: 50 lr: 0.00022749999999999997 loss: -0.5723749995231628
Epoch: 10 iteration: 100 lr: 0.00022749999999999997 loss: 0.3125423192977905
Epoch: 10 iteration: 150 lr: 0.00022749999999999997 loss: 0.2595430910587311
Epoch: 10 iteration: 200 lr: 0.00022749999999999997 loss: -0.7876827716827393
Epoch: 10 iteration: 250 lr: 0.00022749999999999997 loss: 0.32207944989204407
Computing features for evaluation...
Computing features for evaluation...
Epoch: 10
coco val: {'txt_r1': 18.98, 'txt_r5': 40.72, 'txt_r10': 52.22, 'txt_r_mean': 37.306666666666665, 'img_r1': 12.598960415833666, 'img_r5': 31.555377848860456, 'img_r10': 43.1187524990004, 'img_r_mean': 29.09103025456484, 'r_mean': 33.19884846061575}
coco test: {'txt_r1': 18.4, 'txt_r5': 40.0, 'txt_r10': 51.3, 'txt_r_mean': 36.56666666666666, 'img_r1': 12.65093962415034, 'img_r5': 31.391443422630946, 'img_r10': 43.06677329068373, 'img_r_mean': 29.03638544582167, 'r_mean': 32.801526056244164}
Epoch: 11, gamma: 0.332
Epoch: 11 iteration: 0 lr: 0.00021397681324599103 loss: -0.34026050567626953
Epoch: 11 iteration: 50 lr: 0.00021397681324599103 loss: -0.2386927455663681
Epoch: 11 iteration: 100 lr: 0.00021397681324599103 loss: -0.14894789457321167
Epoch: 11 iteration: 150 lr: 0.00021397681324599103 loss: -0.10067954659461975
Epoch: 11 iteration: 200 lr: 0.00021397681324599103 loss: -0.23022054135799408
Epoch: 11 iteration: 250 lr: 0.00021397681324599103 loss: -0.45793771743774414
Computing features for evaluation...
Computing features for evaluation...
Epoch: 11
coco val: {'txt_r1': 18.62, 'txt_r5': 40.64, 'txt_r10': 52.94, 'txt_r_mean': 37.4, 'img_r1': 12.922830867652939, 'img_r5': 32.03118752499, 'img_r10': 43.49460215913635, 'img_r_mean': 29.482873517259765, 'r_mean': 33.441436758629884}
coco test: {'txt_r1': 17.74, 'txt_r5': 40.04, 'txt_r10': 51.3, 'txt_r_mean': 36.36, 'img_r1': 12.722910835665735, 'img_r5': 31.78328668532587, 'img_r10': 43.366653338664534, 'img_r_mean': 29.290950286552047, 'r_mean': 32.82547514327602}
Epoch: 12, gamma: 0.276
Epoch: 12 iteration: 0 lr: 0.00019980746418436736 loss: 0.1621129810810089
Epoch: 12 iteration: 50 lr: 0.00019980746418436736 loss: -0.009299516677856445
Epoch: 12 iteration: 100 lr: 0.00019980746418436736 loss: -0.5970742702484131
Epoch: 12 iteration: 150 lr: 0.00019980746418436736 loss: 0.47076350450515747
Epoch: 12 iteration: 200 lr: 0.00019980746418436736 loss: -0.13326945900917053
Epoch: 12 iteration: 250 lr: 0.00019980746418436736 loss: 0.45385855436325073
Computing features for evaluation...
Computing features for evaluation...
Epoch: 12
coco val: {'txt_r1': 19.36, 'txt_r5': 41.76, 'txt_r10': 53.8, 'txt_r_mean': 38.306666666666665, 'img_r1': 12.510995601759296, 'img_r5': 31.64734106357457, 'img_r10': 43.906437425029985, 'img_r_mean': 29.354924696787947, 'r_mean': 33.83079568172731}
coco test: {'txt_r1': 17.92, 'txt_r5': 40.54, 'txt_r10': 52.52, 'txt_r_mean': 36.99333333333333, 'img_r1': 12.546981207516993, 'img_r5': 31.663334666133547, 'img_r10': 43.59856057576969, 'img_r_mean': 29.26962548314008, 'r_mean': 33.13147940823671}
Epoch: 13, gamma: 0.235
Epoch: 13 iteration: 0 lr: 0.00018514719516857505 loss: -0.5067631006240845
Epoch: 13 iteration: 50 lr: 0.00018514719516857505 loss: 0.2352938950061798
Epoch: 13 iteration: 100 lr: 0.00018514719516857505 loss: -0.2643214464187622
Epoch: 13 iteration: 150 lr: 0.00018514719516857505 loss: 0.23752623796463013
Epoch: 13 iteration: 200 lr: 0.00018514719516857505 loss: 0.07142394781112671
Epoch: 13 iteration: 250 lr: 0.00018514719516857505 loss: -0.08324214816093445
Computing features for evaluation...
Computing features for evaluation...
Epoch: 13
coco val: {'txt_r1': 18.02, 'txt_r5': 40.6, 'txt_r10': 52.58, 'txt_r_mean': 37.06666666666667, 'img_r1': 13.07077169132347, 'img_r5': 32.15113954418233, 'img_r10': 43.834466213514595, 'img_r_mean': 29.685459149673466, 'r_mean': 33.37606290817007}
coco test: {'txt_r1': 18.68, 'txt_r5': 39.98, 'txt_r10': 51.54, 'txt_r_mean': 36.73333333333333, 'img_r1': 12.886845261895242, 'img_r5': 31.747301079568174, 'img_r10': 43.758496601359454, 'img_r_mean': 29.46421431427429, 'r_mean': 33.09877382380381}
Epoch: 14, gamma: 0.209
Epoch: 14 iteration: 0 lr: 0.00017015662717380974 loss: -0.20282623171806335
Epoch: 14 iteration: 50 lr: 0.00017015662717380974 loss: 0.06293128430843353
Epoch: 14 iteration: 100 lr: 0.00017015662717380974 loss: 0.1367354840040207
Epoch: 14 iteration: 150 lr: 0.00017015662717380974 loss: -0.4914567172527313
Epoch: 14 iteration: 200 lr: 0.00017015662717380974 loss: -0.5457226634025574
Epoch: 14 iteration: 250 lr: 0.00017015662717380974 loss: 0.6598182916641235
Computing features for evaluation...
Computing features for evaluation...
Epoch: 14
coco val: {'txt_r1': 18.42, 'txt_r5': 40.68, 'txt_r10': 52.6, 'txt_r_mean': 37.233333333333334, 'img_r1': 13.01079568172731, 'img_r5': 32.52698920431827, 'img_r10': 44.59016393442623, 'img_r_mean': 30.042649606823932, 'r_mean': 33.63799147007863}
coco test: {'txt_r1': 17.36, 'txt_r5': 39.24, 'txt_r10': 51.56, 'txt_r_mean': 36.053333333333335, 'img_r1': 13.110755697720911, 'img_r5': 32.59496201519392, 'img_r10': 44.46621351459416, 'img_r_mean': 30.057310409169663, 'r_mean': 33.0553218712515}
Epoch: 15, gamma: 0.200
Epoch: 15 iteration: 0 lr: 0.000155 loss: -0.3857421278953552
Epoch: 15 iteration: 50 lr: 0.000155 loss: 0.14474812150001526
Epoch: 15 iteration: 100 lr: 0.000155 loss: 0.14783787727355957
Epoch: 15 iteration: 150 lr: 0.000155 loss: 0.287048876285553
Epoch: 15 iteration: 200 lr: 0.000155 loss: 0.4190866947174072
Epoch: 15 iteration: 250 lr: 0.000155 loss: 0.2746019959449768
Computing features for evaluation...
Computing features for evaluation...
Epoch: 15
coco val: {'txt_r1': 19.06, 'txt_r5': 41.82, 'txt_r10': 53.62, 'txt_r_mean': 38.166666666666664, 'img_r1': 13.434626149540184, 'img_r5': 32.86285485805678, 'img_r10': 44.57417033186725, 'img_r_mean': 30.290550446488073, 'r_mean': 34.22860855657737}
coco test: {'txt_r1': 18.2, 'txt_r5': 41.18, 'txt_r10': 52.44, 'txt_r_mean': 37.27333333333333, 'img_r1': 13.290683726509396, 'img_r5': 32.82287085165934, 'img_r10': 44.31827269092363, 'img_r_mean': 30.14394242303079, 'r_mean': 33.70863787818206}
Epoch: 16, gamma: 0.200
Epoch: 16 iteration: 0 lr: 0.00013984337282619026 loss: -0.28232839703559875
Epoch: 16 iteration: 50 lr: 0.00013984337282619026 loss: 0.04332975298166275
Epoch: 16 iteration: 100 lr: 0.00013984337282619026 loss: 0.8832021355628967
Epoch: 16 iteration: 150 lr: 0.00013984337282619026 loss: -0.38278964161872864
Epoch: 16 iteration: 200 lr: 0.00013984337282619026 loss: 0.11864498257637024
Epoch: 16 iteration: 250 lr: 0.00013984337282619026 loss: -0.07094748318195343
Computing features for evaluation...
Computing features for evaluation...
Epoch: 16
coco val: {'txt_r1': 19.46, 'txt_r5': 42.48, 'txt_r10': 55.12, 'txt_r_mean': 39.02, 'img_r1': 13.590563774490203, 'img_r5': 33.406637345061974, 'img_r10': 45.373850459816076, 'img_r_mean': 30.79035052645608, 'r_mean': 34.905175263228045}
coco test: {'txt_r1': 19.12, 'txt_r5': 41.52, 'txt_r10': 54.16, 'txt_r_mean': 38.266666666666666, 'img_r1': 13.582566973210715, 'img_r5': 33.37864854058377, 'img_r10': 45.25389844062375, 'img_r_mean': 30.73837131813941, 'r_mean': 34.50251899240304}
Epoch: 17, gamma: 0.200
Epoch: 17 iteration: 0 lr: 0.00012485280483142487 loss: -0.9415677189826965
Epoch: 17 iteration: 50 lr: 0.00012485280483142487 loss: -0.5497835874557495
Epoch: 17 iteration: 100 lr: 0.00012485280483142487 loss: 0.16091038286685944
Epoch: 17 iteration: 150 lr: 0.00012485280483142487 loss: -0.5314240455627441
Epoch: 17 iteration: 200 lr: 0.00012485280483142487 loss: -0.48017585277557373
Epoch: 17 iteration: 250 lr: 0.00012485280483142487 loss: -0.06742753088474274
Computing features for evaluation...
Computing features for evaluation...
Epoch: 17
coco val: {'txt_r1': 18.38, 'txt_r5': 42.0, 'txt_r10': 53.8, 'txt_r_mean': 38.059999999999995, 'img_r1': 13.874450219912035, 'img_r5': 33.646541383446625, 'img_r10': 45.46581367453019, 'img_r_mean': 30.99560175929628, 'r_mean': 34.52780087964814}
coco test: {'txt_r1': 18.72, 'txt_r5': 40.96, 'txt_r10': 52.74, 'txt_r_mean': 37.473333333333336, 'img_r1': 13.58656537385046, 'img_r5': 33.59856057576969, 'img_r10': 45.56577369052379, 'img_r_mean': 30.916966546714647, 'r_mean': 34.195149940023995}
Epoch: 18, gamma: 0.200
Epoch: 18 iteration: 0 lr: 0.00011019253581563262 loss: -0.22665226459503174
Epoch: 18 iteration: 50 lr: 0.00011019253581563262 loss: 0.3105364143848419
Epoch: 18 iteration: 100 lr: 0.00011019253581563262 loss: -0.6017360687255859
Epoch: 18 iteration: 150 lr: 0.00011019253581563262 loss: -0.10946881771087646
Epoch: 18 iteration: 200 lr: 0.00011019253581563262 loss: 0.5930840969085693
Epoch: 18 iteration: 250 lr: 0.00011019253581563262 loss: -0.5299042463302612
Computing features for evaluation...
Computing features for evaluation...
Epoch: 18
coco val: {'txt_r1': 18.88, 'txt_r5': 41.66, 'txt_r10': 54.32, 'txt_r_mean': 38.28666666666666, 'img_r1': 14.146341463414634, 'img_r5': 33.906437425029985, 'img_r10': 45.813674530187924, 'img_r_mean': 31.288817806210847, 'r_mean': 34.78774223643875}
coco test: {'txt_r1': 19.12, 'txt_r5': 41.68, 'txt_r10': 53.5, 'txt_r_mean': 38.1, 'img_r1': 14.166333466613354, 'img_r5': 33.98640543782487, 'img_r10': 45.84966013594562, 'img_r_mean': 31.33413301346128, 'r_mean': 34.71706650673064}
Epoch: 19, gamma: 0.200
Epoch: 19 iteration: 0 lr: 9.602318675400897e-05 loss: -0.3066856861114502
Epoch: 19 iteration: 50 lr: 9.602318675400897e-05 loss: -0.17421871423721313
Epoch: 19 iteration: 100 lr: 9.602318675400897e-05 loss: 0.14295539259910583
Epoch: 19 iteration: 150 lr: 9.602318675400897e-05 loss: -0.3085940182209015
Epoch: 19 iteration: 200 lr: 9.602318675400897e-05 loss: 0.24928906559944153
Epoch: 19 iteration: 250 lr: 9.602318675400897e-05 loss: -0.5828370451927185
Computing features for evaluation...
Computing features for evaluation...
Epoch: 19
coco val: {'txt_r1': 18.4, 'txt_r5': 41.82, 'txt_r10': 54.68, 'txt_r_mean': 38.300000000000004, 'img_r1': 14.082367053178729, 'img_r5': 34.47820871651339, 'img_r10': 46.353458616553375, 'img_r_mean': 31.638011462081835, 'r_mean': 34.96900573104092}
coco test: {'txt_r1': 19.2, 'txt_r5': 41.32, 'txt_r10': 53.96, 'txt_r_mean': 38.16, 'img_r1': 14.022391043582568, 'img_r5': 34.05437824870052, 'img_r10': 46.0375849660136, 'img_r_mean': 31.37145141943223, 'r_mean': 34.765725709716115}
Epoch: 20, gamma: 0.200
Epoch: 20 iteration: 0 lr: 8.250000000000001e-05 loss: -0.687865138053894
Epoch: 20 iteration: 50 lr: 8.250000000000001e-05 loss: 0.06656238436698914
Epoch: 20 iteration: 100 lr: 8.250000000000001e-05 loss: 0.10606825351715088
Epoch: 20 iteration: 150 lr: 8.250000000000001e-05 loss: -0.3606206774711609
Epoch: 20 iteration: 200 lr: 8.250000000000001e-05 loss: -0.516855001449585
Epoch: 20 iteration: 250 lr: 8.250000000000001e-05 loss: 0.1063995361328125
Computing features for evaluation...
Computing features for evaluation...
Epoch: 20
coco val: {'txt_r1': 19.42, 'txt_r5': 42.92, 'txt_r10': 55.74, 'txt_r_mean': 39.36000000000001, 'img_r1': 14.214314274290285, 'img_r5': 34.60215913634546, 'img_r10': 46.557377049180324, 'img_r_mean': 31.791283486605362, 'r_mean': 35.57564174330268}
coco test: {'txt_r1': 20.32, 'txt_r5': 42.76, 'txt_r10': 54.22, 'txt_r_mean': 39.1, 'img_r1': 14.23030787684926, 'img_r5': 34.44622151139544, 'img_r10': 46.44142343062775, 'img_r_mean': 31.705984272957483, 'r_mean': 35.402992136478744}
Epoch: 21, gamma: 0.200
Epoch: 21 iteration: 0 lr: 6.97711384175914e-05 loss: -0.21475720405578613
Epoch: 21 iteration: 50 lr: 6.97711384175914e-05 loss: -0.34671270847320557
Epoch: 21 iteration: 100 lr: 6.97711384175914e-05 loss: -0.33826878666877747
Epoch: 21 iteration: 150 lr: 6.97711384175914e-05 loss: -0.10392135381698608
Epoch: 21 iteration: 200 lr: 6.97711384175914e-05 loss: 0.7251447439193726
Epoch: 21 iteration: 250 lr: 6.97711384175914e-05 loss: -0.4448509216308594
Computing features for evaluation...
Computing features for evaluation...
Epoch: 21
coco val: {'txt_r1': 19.52, 'txt_r5': 43.7, 'txt_r10': 55.54, 'txt_r_mean': 39.586666666666666, 'img_r1': 14.338264694122351, 'img_r5': 34.91003598560576, 'img_r10': 46.781287485006, 'img_r_mean': 32.00986272157804, 'r_mean': 35.79826469412235}
coco test: {'txt_r1': 19.76, 'txt_r5': 42.54, 'txt_r10': 54.62, 'txt_r_mean': 38.97333333333333, 'img_r1': 14.406237504998002, 'img_r5': 34.51019592163135, 'img_r10': 46.517393042782885, 'img_r_mean': 31.81127548980408, 'r_mean': 35.3923044115687}
Epoch: 22, gamma: 0.200
Epoch: 22 iteration: 0 lr: 5.797606207796559e-05 loss: -0.4769590497016907
Epoch: 22 iteration: 50 lr: 5.797606207796559e-05 loss: 0.4714312255382538
Epoch: 22 iteration: 100 lr: 5.797606207796559e-05 loss: -0.0077140554785728455
Epoch: 22 iteration: 150 lr: 5.797606207796559e-05 loss: -0.12021001428365707
Epoch: 22 iteration: 200 lr: 5.797606207796559e-05 loss: -0.0014841780066490173
Epoch: 22 iteration: 250 lr: 5.797606207796559e-05 loss: -0.06714646518230438
Computing features for evaluation...
Computing features for evaluation...
Epoch: 22
coco val: {'txt_r1': 19.6, 'txt_r5': 43.42, 'txt_r10': 55.76, 'txt_r_mean': 39.593333333333334, 'img_r1': 14.57017193122751, 'img_r5': 34.718112754898044, 'img_r10': 46.48140743702519, 'img_r_mean': 31.923230707716915, 'r_mean': 35.75828202052512}
coco test: {'txt_r1': 20.5, 'txt_r5': 42.38, 'txt_r10': 54.34, 'txt_r_mean': 39.07333333333333, 'img_r1': 14.446221511395441, 'img_r5': 34.21431427429028, 'img_r10': 46.26949220311875, 'img_r_mean': 31.643342662934828, 'r_mean': 35.358337998134076}
Epoch: 23, gamma: 0.200
Epoch: 23 iteration: 0 lr: 4.724400030577786e-05 loss: -0.33012133836746216
Epoch: 23 iteration: 50 lr: 4.724400030577786e-05 loss: -0.3042541444301605
Epoch: 23 iteration: 100 lr: 4.724400030577786e-05 loss: 0.022292636334896088
Epoch: 23 iteration: 150 lr: 4.724400030577786e-05 loss: 0.3158537745475769
Epoch: 23 iteration: 200 lr: 4.724400030577786e-05 loss: -0.16166701912879944
Epoch: 23 iteration: 250 lr: 4.724400030577786e-05 loss: 0.26842328906059265
Computing features for evaluation...
Computing features for evaluation...
Epoch: 23
coco val: {'txt_r1': 19.14, 'txt_r5': 43.16, 'txt_r10': 55.7, 'txt_r_mean': 39.333333333333336, 'img_r1': 14.514194322271091, 'img_r5': 34.85405837664934, 'img_r10': 46.59736105557777, 'img_r_mean': 31.98853791816607, 'r_mean': 35.6609356257497}
coco test: {'txt_r1': 20.36, 'txt_r5': 42.84, 'txt_r10': 55.32, 'txt_r_mean': 39.50666666666667, 'img_r1': 14.426229508196721, 'img_r5': 34.14234306277489, 'img_r10': 46.08156737305078, 'img_r_mean': 31.550046648007463, 'r_mean': 35.52835665733706}
Epoch: 24, gamma: 0.200
Epoch: 24 iteration: 0 lr: 3.769253581563263e-05 loss: -0.3044487535953522
Epoch: 24 iteration: 50 lr: 3.769253581563263e-05 loss: 0.39506223797798157
Epoch: 24 iteration: 100 lr: 3.769253581563263e-05 loss: -0.1519729197025299
Epoch: 24 iteration: 150 lr: 3.769253581563263e-05 loss: -0.44683516025543213
Epoch: 24 iteration: 200 lr: 3.769253581563263e-05 loss: -0.6504060626029968
Epoch: 24 iteration: 250 lr: 3.769253581563263e-05 loss: -0.19650176167488098
Computing features for evaluation...
Computing features for evaluation...
Epoch: 24
coco val: {'txt_r1': 20.06, 'txt_r5': 42.68, 'txt_r10': 55.44, 'txt_r_mean': 39.39333333333333, 'img_r1': 14.614154338264694, 'img_r5': 35.29388244702119, 'img_r10': 47.26109556177529, 'img_r_mean': 32.389710782353724, 'r_mean': 35.89152205784353}
coco test: {'txt_r1': 20.38, 'txt_r5': 42.52, 'txt_r10': 54.92, 'txt_r_mean': 39.27333333333333, 'img_r1': 14.722111155537785, 'img_r5': 34.83006797281087, 'img_r10': 46.869252299080365, 'img_r_mean': 32.140477142476335, 'r_mean': 35.706905237904834}
Epoch: 25, gamma: 0.200
Epoch: 25 iteration: 0 lr: 2.9426316451256386e-05 loss: 0.10228502005338669
Epoch: 25 iteration: 50 lr: 2.9426316451256386e-05 loss: 0.02058348059654236
Epoch: 25 iteration: 100 lr: 2.9426316451256386e-05 loss: -0.110775887966156
Epoch: 25 iteration: 150 lr: 2.9426316451256386e-05 loss: -0.2704155147075653
Epoch: 25 iteration: 200 lr: 2.9426316451256386e-05 loss: 0.041183631867170334
Epoch: 25 iteration: 250 lr: 2.9426316451256386e-05 loss: -0.2531593441963196
Computing features for evaluation...
Computing features for evaluation...
Epoch: 25
coco val: {'txt_r1': 19.54, 'txt_r5': 42.42, 'txt_r10': 54.82, 'txt_r_mean': 38.92666666666667, 'img_r1': 14.642143142742903, 'img_r5': 34.85405837664934, 'img_r10': 46.845261895241904, 'img_r_mean': 32.113821138211385, 'r_mean': 35.52024390243903}
coco test: {'txt_r1': 20.12, 'txt_r5': 41.86, 'txt_r10': 54.42, 'txt_r_mean': 38.800000000000004, 'img_r1': 14.674130347860856, 'img_r5': 34.60615753698521, 'img_r10': 46.829268292682926, 'img_r_mean': 32.036518725842996, 'r_mean': 35.4182593629215}
Epoch: 26, gamma: 0.200
Epoch: 26 iteration: 0 lr: 2.2535908641822855e-05 loss: -0.05754963308572769
Epoch: 26 iteration: 50 lr: 2.2535908641822855e-05 loss: -0.15947675704956055
Epoch: 26 iteration: 100 lr: 2.2535908641822855e-05 loss: 0.23592060804367065
Epoch: 26 iteration: 150 lr: 2.2535908641822855e-05 loss: -0.31553971767425537
Epoch: 26 iteration: 200 lr: 2.2535908641822855e-05 loss: -0.3375014662742615
Epoch: 26 iteration: 250 lr: 2.2535908641822855e-05 loss: -0.31750810146331787
Computing features for evaluation...
Computing features for evaluation...
Epoch: 26
coco val: {'txt_r1': 19.3, 'txt_r5': 42.38, 'txt_r10': 55.16, 'txt_r_mean': 38.946666666666665, 'img_r1': 14.602159136345461, 'img_r5': 34.94202319072371, 'img_r10': 47.01319472211116, 'img_r_mean': 32.185792349726775, 'r_mean': 35.56622950819672}
coco test: {'txt_r1': 20.18, 'txt_r5': 42.06, 'txt_r10': 54.1, 'txt_r_mean': 38.78, 'img_r1': 14.818072770891643, 'img_r5': 34.58216713314674, 'img_r10': 46.593362654938026, 'img_r_mean': 31.997867519658808, 'r_mean': 35.388933759829406}
Epoch: 27, gamma: 0.200
Epoch: 27 iteration: 0 lr: 1.7096805137202738e-05 loss: -0.10159443318843842
Epoch: 27 iteration: 50 lr: 1.7096805137202738e-05 loss: -0.2504361569881439
Epoch: 27 iteration: 100 lr: 1.7096805137202738e-05 loss: -0.05296333134174347
Epoch: 27 iteration: 150 lr: 1.7096805137202738e-05 loss: -0.30587038397789
Epoch: 27 iteration: 200 lr: 1.7096805137202738e-05 loss: -0.6555557250976562
Epoch: 27 iteration: 250 lr: 1.7096805137202738e-05 loss: -0.3346867263317108
Computing features for evaluation...
Computing features for evaluation...
Epoch: 27
coco val: {'txt_r1': 19.32, 'txt_r5': 43.2, 'txt_r10': 55.62, 'txt_r_mean': 39.38, 'img_r1': 14.514194322271091, 'img_r5': 35.19792083166733, 'img_r10': 46.917233106757294, 'img_r_mean': 32.20978275356524, 'r_mean': 35.79489137678262}
coco test: {'txt_r1': 19.84, 'txt_r5': 42.32, 'txt_r10': 54.12, 'txt_r_mean': 38.76, 'img_r1': 14.706117552978808, 'img_r5': 34.65013994402239, 'img_r10': 46.62135145941623, 'img_r_mean': 31.992536318805815, 'r_mean': 35.376268159402905}
Epoch: 28, gamma: 0.200
Epoch: 28 iteration: 0 lr: 1.3168597893598175e-05 loss: -0.060578376054763794
Epoch: 28 iteration: 50 lr: 1.3168597893598175e-05 loss: -0.502825140953064
Epoch: 28 iteration: 100 lr: 1.3168597893598175e-05 loss: -0.08314596861600876
Epoch: 28 iteration: 150 lr: 1.3168597893598175e-05 loss: -0.18819916248321533
Epoch: 28 iteration: 200 lr: 1.3168597893598175e-05 loss: 0.043348558247089386
Epoch: 28 iteration: 250 lr: 1.3168597893598175e-05 loss: -0.3972356915473938
Computing features for evaluation...
Computing features for evaluation...
Epoch: 28
coco val: {'txt_r1': 19.62, 'txt_r5': 42.82, 'txt_r10': 55.84, 'txt_r_mean': 39.42666666666667, 'img_r1': 14.642143142742903, 'img_r5': 35.15793682526989, 'img_r10': 47.06917233106757, 'img_r_mean': 32.28975076636012, 'r_mean': 35.858208716513396}
coco test: {'txt_r1': 20.42, 'txt_r5': 42.44, 'txt_r10': 54.28, 'txt_r_mean': 39.04666666666667, 'img_r1': 14.742103158736505, 'img_r5': 34.67013194722111, 'img_r10': 46.89724110355858, 'img_r_mean': 32.1031587365054, 'r_mean': 35.57491270158603}
Epoch: 29, gamma: 0.200
Epoch: 29 iteration: 0 lr: 1.0794325171600358e-05 loss: -0.11102907359600067
Epoch: 29 iteration: 50 lr: 1.0794325171600358e-05 loss: -0.26743975281715393
Epoch: 29 iteration: 100 lr: 1.0794325171600358e-05 loss: -0.3959043622016907
Epoch: 29 iteration: 150 lr: 1.0794325171600358e-05 loss: -0.5416654348373413
Epoch: 29 iteration: 200 lr: 1.0794325171600358e-05 loss: -0.2686673402786255
Epoch: 29 iteration: 250 lr: 1.0794325171600358e-05 loss: -0.15682968497276306
Computing features for evaluation...
Computing features for evaluation...
Epoch: 29
coco val: {'txt_r1': 19.26, 'txt_r5': 42.56, 'txt_r10': 54.74, 'txt_r_mean': 38.85333333333333, 'img_r1': 14.682127149140344, 'img_r5': 35.141943222710914, 'img_r10': 47.02119152339064, 'img_r_mean': 32.28175396508063, 'r_mean': 35.56754364920698}
coco test: {'txt_r1': 19.88, 'txt_r5': 41.94, 'txt_r10': 53.84, 'txt_r_mean': 38.553333333333335, 'img_r1': 14.74610155937625, 'img_r5': 34.694122351059576, 'img_r10': 46.92123150739704, 'img_r_mean': 32.120485139277626, 'r_mean': 35.33690923630548}
Visualization
In order to compare the performance of different algorithms, we also train CLIP models using OpenCLIP and SogCLR with constant gamma. Notebooks for training CLIP models using the two algorithms are available here and here, respectively. We plot the training curves of the mean validation recall values of the three algorithms.
clip_recall_vals = [9.146024256963882, 25.643747834199658, 29.270318539250965, 30.15803545248567, 30.758616553378648, 30.071351459416235, 30.393121418099422, 30.48455817672931, 30.86781287485006, 30.960474476875916, 30.23930161268826, 30.297093162734903, 30.965095295215246, 31.358384646141545, 31.467666266826605, 30.952405704384915, 31.01773290683726, 31.05107556977209, 31.651619352259097, 31.91153405304545, 31.72560575769692, 31.692890843662532, 31.85492869518859, 32.204224976675995, 32.286870585099294, 32.64414634146342, 32.50149940023991, 32.45683726509397, 32.46283220045315, 32.77081167532987]
sogclr_const_gamma_recall_vals = [8.643449286951887, 20.795427162468346, 25.186021591363456, 27.750850326536053, 28.922504331600692, 29.124374250299883, 29.839438891110223, 29.683995735039318, 31.367840863654536, 32.42836332133814, 31.349722777555648, 32.35694388911102, 31.718447287751566, 32.2727469012395, 31.900145275223245, 32.71076636012261, 32.902112488338, 33.1586818605891, 34.02394908703185, 34.01059442889511, 33.840582433693186, 34.06315873650539, 33.859892043182725, 34.69845661735305, 34.67579101692657, 34.69047181127549, 34.87510595761695, 34.759770758363324, 34.9390737038518, 34.88375982940157]
sogclr_cosine_gamma_recall_vals = [8.667439690790351, 26.009160335865655, 29.73834332933493, 30.173495934959348, 31.42988004798081, 32.007712914834066, 32.069047047847526, 31.48698787151806, 32.637692922830865, 32.831547381047585, 33.19884846061575, 33.441436758629884, 33.83079568172731, 33.37606290817007, 33.63799147007863, 34.22860855657737, 34.905175263228045, 34.52780087964814, 34.78774223643875, 34.96900573104092, 35.57564174330268, 35.79826469412235, 35.75828202052512, 35.6609356257497, 35.89152205784353, 35.52024390243903, 35.56622950819672, 35.79489137678262, 35.858208716513396, 35.56754364920698]
import matplotlib.pyplot as plt
import numpy as np
epochs = np.arange(1, 31)
plt.plot(epochs, clip_recall_vals, label='OpenCLIP', ls=':', marker='+', color='blue')
plt.plot(epochs, sogclr_const_gamma_recall_vals, label='SogCLR (Constant $\\gamma$)', marker='*', color='orange')
plt.plot(epochs, sogclr_cosine_gamma_recall_vals, label='SogCLR (Consine $\\gamma$)')
plt.ylabel('Mean Validation Recall', fontsize=18)
plt.xlabel('Epoch', fontsize=18)
plt.legend(fontsize=16)
plt.show()
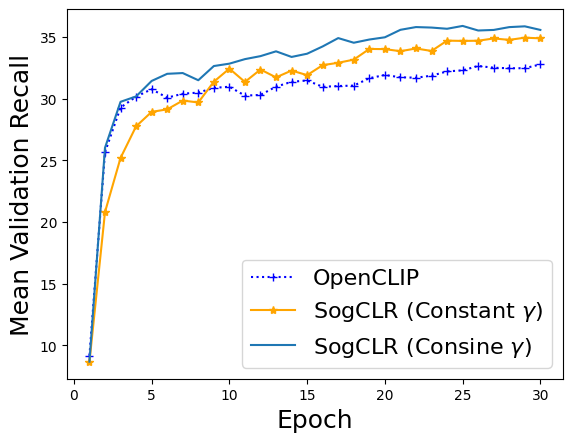
From the above figure we can see that with constant gamma, the performance of SogCLR in early stage is worse than that of CLIP. While with cosine gamma, the performance of SogCLR is better than that of CLIP throughout training.