Multiple Instance Deep AUC Maximization on Tabular Dataset
Introduction
In this tutorial, we will learn how to quickly train a simple Feed Forward Neural Network (FFNN) model by optimizing Multiple Instance Deep AUC Maximization (MIDAM) under our novel MIDAMLoss and MIDAM optimizer [Ref] method on a binary classification task on MUSK2 dataset. Please note that MIDAMLoss is a wrapper function for different types of MIDAM losses. It currently supports two primary modes:
MIDAMLoss(mode='attention'): This mode usesMIDAM_attention_pooling_lossas the backend and utilizes theMIDAMoptimizer for optimization.MIDAMLoss(mode='softmax'): This mode usesMIDAM_softmax_pooling_lossas the backend and utilizes theMIDAMoptimizer for optimization.
In this tutorial, we focus on attention pooling (MIDAM-att), i.e., MIDAMLoss(mode='attention'). For other tutorials, please refer to MIDAM-att-image, MIDAM-smx-tabular. After completion of this tutorial, you should be able to use LibAUC to train your own models on your own datasets.
Reference:
If you find this tutorial helpful in your work, please cite our library paper and the following papers:
@inproceedings{zhu2023mil,
title={Provable Multi-instance Deep AUC Maximization with Stochastic Pooling},
author={Zhu, Dixian and Wang, Bokun and Chen, Zhi and Wang, Yaxing and Sonka, Milan and Wu, Xiaodong and Yang, Tianbao},
booktitle={International Conference on Machine Learning},
year={2023},
organization={PMLR}
}
Install LibAUC
Let’s start with installing our library here. In this tutorial, we will use the lastest version for LibAUC by using pip install -U.
!pip install -U libauc
Importing LibAUC
Import required libraries to use
import torch
import matplotlib.pyplot as plt
import numpy as np
from libauc.optimizers import MIDAM
from libauc.losses import MIDAMLoss
from libauc.models import FFNN_stoc_att
from libauc.utils import set_all_seeds, collate_fn, MIL_sampling, MIL_evaluate_auc
from libauc.sampler import DualSampler
from libauc.datasets import MUSK2, CustomDataset
Reproducibility
These functions limit the number of sources of randomness behaviors, such as model intialization, data shuffling, etcs. However, completely reproducible results are not guaranteed across PyTorch releases [Ref].
def set_all_seeds(SEED):
# REPRODUCIBILITY
torch.manual_seed(SEED)
np.random.seed(SEED)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
Introduction for Loss and Optimizer
In this section, we will introduce pAUC optimization algorithm and how to utilize MIDAMLoss function and MIDAM optimizer.
HyperParameters
The hyper-parameters: batch size (bag-level), instance batch size (instance-level), postive sampling rate, learning rate, weight decay and margin for AUC loss.
# HyperParameters
SEED = 123
set_all_seeds(SEED)
batch_size = 16
instance_batch_size = 4
sampling_rate = 0.5
lr = 1e-2
weight_decay = 1e-4
margin = 1.0
momentum = 0.1
gamma = 0.9
Load Data, initialize model and loss
In this step, we will use the MUSK2 as benchmark dataset [Ref]. Import data to dataloader. We extend the traditional FFNN with an additional attention module: FFNN_stoc_att. Data format: a list with length equals to number of bags. Each bag is an array with shape: (Number of instances for this bag, Dimension)
(train_data, train_labels), (test_data, test_labels) = MUSK2()
traindSet = CustomDataset(train_data, train_labels, return_index=True)
testSet = CustomDataset(test_data, test_labels, return_index=True)
DIMS=166
sampler = DualSampler(dataset=traindSet, batch_size=batch_size, shuffle=True, sampling_rate=sampling_rate)
trainloader = torch.utils.data.DataLoader(dataset=traindSet, sampler=sampler, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
testloader = torch.utils.data.DataLoader(testSet, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = FFNN_stoc_att(input_dim=DIMS, hidden_sizes=(DIMS, ), num_classes=1).to(device)
Loss = MIDAMLoss(mode='attention',data_len=len(traindSet), gamma=gamma, margin=margin)
optimizer = MIDAM(model.parameters(), loss_fn=Loss, lr=lr, weight_decay=weight_decay, momentum=momentum)
Training
total_epochs = 100
decay_epoch = [50, 75]
train_auc = np.zeros(total_epochs)
test_auc = np.zeros(total_epochs)
for epoch in range(total_epochs):
if epoch in decay_epoch:
optimizer.update_lr(decay_factor=10)
Loss.update_smoothing(decay_factor=2)
for idx, data in enumerate(trainloader):
y_pred = []
sd = []
train_data_bags, train_labels, ids = data
for i in range(len(ids)):
tmp_pred, tmp_sd = MIL_sampling(bag_X=train_data_bags[i], model=model, instance_batch_size=instance_batch_size, mode='att')
y_pred.append(tmp_pred)
sd.append(tmp_sd)
y_pred = torch.cat(y_pred, dim=0)
sd = torch.cat(sd, dim=0)
ids = torch.from_numpy(np.array(ids))
train_labels = torch.from_numpy(np.array(train_labels))
loss = Loss(y_pred=(y_pred,sd), y_true=train_labels, index=ids)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
single_tr_auc = MIL_evaluate_auc(trainloader, model, mode='att')
single_te_auc = MIL_evaluate_auc(testloader, model, mode='att')
train_auc[epoch] = single_tr_auc
test_auc[epoch] = single_te_auc
model.train()
print ('Epoch=%s, BatchID=%s, Tr_AUC=%.4f, Test_AUC=%.4f, lr=%.4f'%(epoch, idx, single_tr_auc, single_te_auc, optimizer.lr))
Epoch=0, BatchID=5, Tr_AUC=0.3338, Test_AUC=0.1250, lr=0.0100
Epoch=1, BatchID=5, Tr_AUC=0.3099, Test_AUC=0.1250, lr=0.0100
Epoch=2, BatchID=5, Tr_AUC=0.3025, Test_AUC=0.1250, lr=0.0100
Epoch=3, BatchID=5, Tr_AUC=0.3372, Test_AUC=0.1667, lr=0.0100
Epoch=4, BatchID=5, Tr_AUC=0.3993, Test_AUC=0.2083, lr=0.0100
Epoch=5, BatchID=5, Tr_AUC=0.3615, Test_AUC=0.2083, lr=0.0100
Epoch=6, BatchID=5, Tr_AUC=0.4484, Test_AUC=0.2083, lr=0.0100
Epoch=7, BatchID=5, Tr_AUC=0.4670, Test_AUC=0.2083, lr=0.0100
Epoch=8, BatchID=5, Tr_AUC=0.4605, Test_AUC=0.2083, lr=0.0100
Epoch=9, BatchID=5, Tr_AUC=0.4891, Test_AUC=0.2083, lr=0.0100
Epoch=10, BatchID=5, Tr_AUC=0.5482, Test_AUC=0.2083, lr=0.0100
Epoch=11, BatchID=5, Tr_AUC=0.5260, Test_AUC=0.2917, lr=0.0100
Epoch=12, BatchID=5, Tr_AUC=0.6211, Test_AUC=0.2500, lr=0.0100
Epoch=13, BatchID=5, Tr_AUC=0.5412, Test_AUC=0.2917, lr=0.0100
Epoch=14, BatchID=5, Tr_AUC=0.6289, Test_AUC=0.3750, lr=0.0100
Epoch=15, BatchID=5, Tr_AUC=0.6185, Test_AUC=0.4583, lr=0.0100
Epoch=16, BatchID=5, Tr_AUC=0.6241, Test_AUC=0.4583, lr=0.0100
Epoch=17, BatchID=5, Tr_AUC=0.6549, Test_AUC=0.4583, lr=0.0100
Epoch=18, BatchID=5, Tr_AUC=0.6901, Test_AUC=0.3750, lr=0.0100
Epoch=19, BatchID=5, Tr_AUC=0.6727, Test_AUC=0.3750, lr=0.0100
Epoch=20, BatchID=5, Tr_AUC=0.6797, Test_AUC=0.4167, lr=0.0100
Epoch=21, BatchID=5, Tr_AUC=0.6879, Test_AUC=0.4583, lr=0.0100
Epoch=22, BatchID=5, Tr_AUC=0.6997, Test_AUC=0.5000, lr=0.0100
Epoch=23, BatchID=5, Tr_AUC=0.7127, Test_AUC=0.5833, lr=0.0100
Epoch=24, BatchID=5, Tr_AUC=0.7509, Test_AUC=0.5417, lr=0.0100
Epoch=25, BatchID=5, Tr_AUC=0.7161, Test_AUC=0.5833, lr=0.0100
Epoch=26, BatchID=5, Tr_AUC=0.7365, Test_AUC=0.5000, lr=0.0100
Epoch=27, BatchID=5, Tr_AUC=0.8173, Test_AUC=0.5833, lr=0.0100
Epoch=28, BatchID=5, Tr_AUC=0.8051, Test_AUC=0.5417, lr=0.0100
Epoch=29, BatchID=5, Tr_AUC=0.7760, Test_AUC=0.5833, lr=0.0100
Epoch=30, BatchID=5, Tr_AUC=0.8464, Test_AUC=0.5833, lr=0.0100
Epoch=31, BatchID=5, Tr_AUC=0.8507, Test_AUC=0.6667, lr=0.0100
Epoch=32, BatchID=5, Tr_AUC=0.8885, Test_AUC=0.7083, lr=0.0100
Epoch=33, BatchID=5, Tr_AUC=0.8885, Test_AUC=0.7500, lr=0.0100
Epoch=34, BatchID=5, Tr_AUC=0.8906, Test_AUC=0.7500, lr=0.0100
Epoch=35, BatchID=5, Tr_AUC=0.8733, Test_AUC=0.7083, lr=0.0100
Epoch=36, BatchID=5, Tr_AUC=0.9210, Test_AUC=0.7500, lr=0.0100
Epoch=37, BatchID=5, Tr_AUC=0.8967, Test_AUC=0.6667, lr=0.0100
Epoch=38, BatchID=5, Tr_AUC=0.9062, Test_AUC=0.7500, lr=0.0100
Epoch=39, BatchID=5, Tr_AUC=0.9280, Test_AUC=0.7917, lr=0.0100
Epoch=40, BatchID=5, Tr_AUC=0.9219, Test_AUC=0.8333, lr=0.0100
Epoch=41, BatchID=5, Tr_AUC=0.9457, Test_AUC=0.9167, lr=0.0100
Epoch=42, BatchID=5, Tr_AUC=0.9631, Test_AUC=0.8750, lr=0.0100
Epoch=43, BatchID=5, Tr_AUC=0.9570, Test_AUC=0.8750, lr=0.0100
Epoch=44, BatchID=5, Tr_AUC=0.9592, Test_AUC=0.8333, lr=0.0100
Epoch=45, BatchID=5, Tr_AUC=0.9605, Test_AUC=0.8750, lr=0.0100
Epoch=46, BatchID=5, Tr_AUC=0.9514, Test_AUC=0.8750, lr=0.0100
Epoch=47, BatchID=5, Tr_AUC=0.9657, Test_AUC=0.8333, lr=0.0100
Epoch=48, BatchID=5, Tr_AUC=0.9796, Test_AUC=0.8750, lr=0.0100
Epoch=49, BatchID=5, Tr_AUC=0.9774, Test_AUC=0.9167, lr=0.0100
Reducing learning rate to 0.00100 @ T=300!
Updating regularizer @ T=300!
Epoch=50, BatchID=5, Tr_AUC=0.9648, Test_AUC=0.9167, lr=0.0010
Epoch=51, BatchID=5, Tr_AUC=0.9753, Test_AUC=0.9167, lr=0.0010
Epoch=52, BatchID=5, Tr_AUC=0.9865, Test_AUC=0.9167, lr=0.0010
Epoch=53, BatchID=5, Tr_AUC=0.9766, Test_AUC=0.9167, lr=0.0010
Epoch=54, BatchID=5, Tr_AUC=0.9878, Test_AUC=0.9167, lr=0.0010
Epoch=55, BatchID=5, Tr_AUC=0.9731, Test_AUC=0.9167, lr=0.0010
Epoch=56, BatchID=5, Tr_AUC=0.9848, Test_AUC=0.9167, lr=0.0010
Epoch=57, BatchID=5, Tr_AUC=0.9761, Test_AUC=0.9167, lr=0.0010
Epoch=58, BatchID=5, Tr_AUC=0.9800, Test_AUC=0.9167, lr=0.0010
Epoch=59, BatchID=5, Tr_AUC=0.9787, Test_AUC=0.9167, lr=0.0010
Epoch=60, BatchID=5, Tr_AUC=0.9826, Test_AUC=0.9167, lr=0.0010
Epoch=61, BatchID=5, Tr_AUC=0.9826, Test_AUC=0.9167, lr=0.0010
Epoch=62, BatchID=5, Tr_AUC=0.9740, Test_AUC=0.9167, lr=0.0010
Epoch=63, BatchID=5, Tr_AUC=0.9705, Test_AUC=0.9167, lr=0.0010
Epoch=64, BatchID=5, Tr_AUC=0.9839, Test_AUC=0.9167, lr=0.0010
Epoch=65, BatchID=5, Tr_AUC=0.9818, Test_AUC=0.9167, lr=0.0010
Epoch=66, BatchID=5, Tr_AUC=0.9822, Test_AUC=0.9167, lr=0.0010
Epoch=67, BatchID=5, Tr_AUC=0.9861, Test_AUC=0.9167, lr=0.0010
Epoch=68, BatchID=5, Tr_AUC=0.9844, Test_AUC=0.9167, lr=0.0010
Epoch=69, BatchID=5, Tr_AUC=0.9874, Test_AUC=0.9167, lr=0.0010
Epoch=70, BatchID=5, Tr_AUC=0.9757, Test_AUC=0.9167, lr=0.0010
Epoch=71, BatchID=5, Tr_AUC=0.9831, Test_AUC=0.9167, lr=0.0010
Epoch=72, BatchID=5, Tr_AUC=0.9852, Test_AUC=0.9167, lr=0.0010
Epoch=73, BatchID=5, Tr_AUC=0.9805, Test_AUC=0.9167, lr=0.0010
Epoch=74, BatchID=5, Tr_AUC=0.9861, Test_AUC=0.9167, lr=0.0010
Reducing learning rate to 0.00010 @ T=450!
Updating regularizer @ T=450!
Epoch=75, BatchID=5, Tr_AUC=0.9809, Test_AUC=0.9167, lr=0.0001
Epoch=76, BatchID=5, Tr_AUC=0.9913, Test_AUC=0.9167, lr=0.0001
Epoch=77, BatchID=5, Tr_AUC=0.9839, Test_AUC=0.9167, lr=0.0001
Epoch=78, BatchID=5, Tr_AUC=0.9883, Test_AUC=0.9167, lr=0.0001
Epoch=79, BatchID=5, Tr_AUC=0.9844, Test_AUC=0.9167, lr=0.0001
Epoch=80, BatchID=5, Tr_AUC=0.9896, Test_AUC=0.9167, lr=0.0001
Epoch=81, BatchID=5, Tr_AUC=0.9805, Test_AUC=0.9167, lr=0.0001
Epoch=82, BatchID=5, Tr_AUC=0.9887, Test_AUC=0.9167, lr=0.0001
Epoch=83, BatchID=5, Tr_AUC=0.9818, Test_AUC=0.9167, lr=0.0001
Epoch=84, BatchID=5, Tr_AUC=0.9861, Test_AUC=0.9167, lr=0.0001
Epoch=85, BatchID=5, Tr_AUC=0.9861, Test_AUC=0.9167, lr=0.0001
Epoch=86, BatchID=5, Tr_AUC=0.9848, Test_AUC=0.9167, lr=0.0001
Epoch=87, BatchID=5, Tr_AUC=0.9852, Test_AUC=0.9167, lr=0.0001
Epoch=88, BatchID=5, Tr_AUC=0.9870, Test_AUC=0.9167, lr=0.0001
Epoch=89, BatchID=5, Tr_AUC=0.9770, Test_AUC=0.9167, lr=0.0001
Epoch=90, BatchID=5, Tr_AUC=0.9939, Test_AUC=0.9167, lr=0.0001
Epoch=91, BatchID=5, Tr_AUC=0.9822, Test_AUC=0.9167, lr=0.0001
Epoch=92, BatchID=5, Tr_AUC=0.9770, Test_AUC=0.9167, lr=0.0001
Epoch=93, BatchID=5, Tr_AUC=0.9822, Test_AUC=0.9167, lr=0.0001
Epoch=94, BatchID=5, Tr_AUC=0.9861, Test_AUC=0.9167, lr=0.0001
Epoch=95, BatchID=5, Tr_AUC=0.9878, Test_AUC=0.9167, lr=0.0001
Epoch=96, BatchID=5, Tr_AUC=0.9844, Test_AUC=0.9167, lr=0.0001
Epoch=97, BatchID=5, Tr_AUC=0.9688, Test_AUC=0.9167, lr=0.0001
Epoch=98, BatchID=5, Tr_AUC=0.9857, Test_AUC=0.9167, lr=0.0001
Epoch=99, BatchID=5, Tr_AUC=0.9909, Test_AUC=0.9167, lr=0.0001
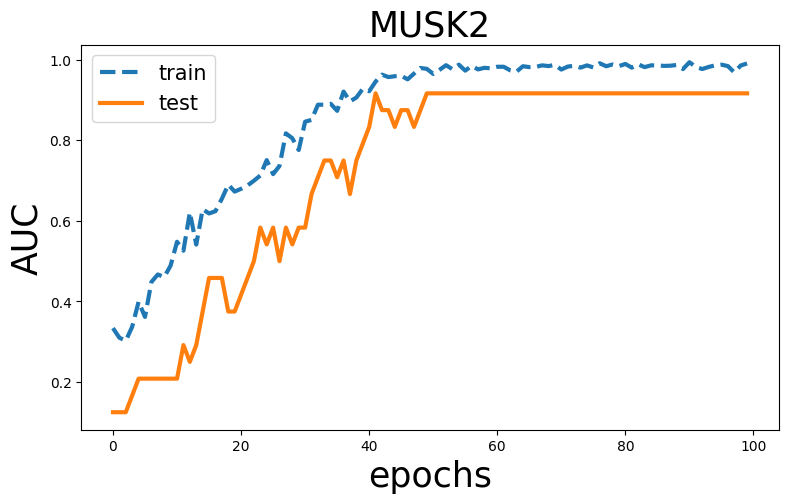
Visualization
plt.rcParams["figure.figsize"] = (9,5)
x=np.arange(len(train_auc))
plt.figure()
plt.plot(x, train_auc, linestyle='--', label='train', linewidth=3)
plt.plot(x, test_auc, label='test', linewidth=3)
plt.title('MUSK2',fontsize=25)
plt.legend(fontsize=15)
plt.ylabel('AUC',fontsize=25)
plt.xlabel('epochs',fontsize=25)