Distributed Training
Introduction
This tutorial demonstrates how to perform distributed training with LibAUC. We provide example scripts for:
Optimizing AUCMLoss + PESG.
Optimizing APLoss + SOAP.
Optimizing pAUC_DRO_Loss + SOPAs.
Optimizing pAUC_CVaR_Loss + SOPA.
Optimizing tpAUC_KL_Loss + SOTAs.
Optimizing NDCGLoss + SONG.
Download example scripts from examples folder in LibAUC Repository. Run the following comand based on number of GPUs you have.
The entry command is:
torchrun --nproc_per_node=<NUM_GPUS> 20_Distributed_Training_for_Optimizing_AUROC.py
# or torchrun --nproc_per_node=<NUM_GPUS> 20_Distributed_Training_for_Optimizing_AUPRC.py
# or torchrun --nproc_per_node=<NUM_GPUS> 20_Distributed_Training_for_Optimizing_NDCG.py
Distributed Training with AUCMLoss and PESG: A Walkthrough
In the following, we provide a walkthrough of distributed training using AUCMLoss and PESG. We train a ResNet20
model by optimizing AUROC using our novel AUCMLoss
and PESG optimizer [Ref]
on a binary image classification task on Cifar10.
After completing this example, you can further adapt the scripts to fit your specific training requirements.
Importing LibAUC
Import required packages to use.
from libauc.losses import AUCMLoss
from libauc.optimizers import PESG
from libauc.models import resnet20 as ResNet20
from libauc.datasets import CIFAR10
from libauc.utils import ImbalancedDataGenerator
from libauc.sampler import DistributedDualSampler
from libauc.metrics import auc_roc_score
import torch
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from PIL import Image
import numpy as np
import torchvision.transforms as transforms
from torch.utils.data import Dataset
import os
Distributed Training Initialization
Initialize distributed training environment.
local_rank = int(os.environ.get("LOCAL_RANK", 0))
dist.init_process_group("nccl", device_id=local_rank)
world_size = dist.get_world_size()
device = torch.device("cuda", local_rank)
Reproducibility
The following function set_all_seeds limits the number of sources
of randomness behaviors, such as model intialization, data shuffling,
etcs. However, completely reproducible results are not guaranteed
across PyTorch releases
[Ref].
def set_all_seeds(SEED):
# REPRODUCIBILITY
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.cuda.manual_seed_all(SEED)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_all_seeds(2026)
Image Dataset
Now we define the data input pipeline such as data
augmentations. In this tutorial, we use RandomCrop,
RandomHorizontalFlip.
class ImageDataset(Dataset):
def __init__(self, images, targets, image_size=32, crop_size=30, mode='train'):
self.images = images.astype(np.uint8)
self.targets = targets
self.mode = mode
self.transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.RandomCrop((crop_size, crop_size), padding=None),
transforms.RandomHorizontalFlip(),
transforms.Resize((image_size, image_size)),
])
self.transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((image_size, image_size)),
])
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx]
target = self.targets[idx]
image = Image.fromarray(image.astype('uint8'))
if self.mode == 'train':
image = self.transform_train(image)
else:
image = self.transform_test(image)
return image, target
Evaluation Function
Since the samples are distributed across multiple GPUs, we need to gather predictions from all GPUs in order to compute the AUC for evaluation.
def distributed_gather_tensor(local_tensor, device):
"""
Gathers a 1-D float tensor from all ranks onto rank 0.
Handles uneven shard sizes.
Returns concatenated tensor on rank 0 (CPU), None on other ranks.
"""
assert local_tensor.dim() == 1, "Expected 1-D tensor"
local_tensor = local_tensor.to(device).contiguous()
# share sizes and pad to max size
local_size = torch.tensor([local_tensor.shape[0]], dtype=torch.long, device=device)
all_sizes = [torch.zeros(1, dtype=torch.long, device=device)
for _ in range(world_size)]
dist.all_gather(all_sizes, local_size)
max_size = max(s.item() for s in all_sizes)
pad = max_size - local_tensor.shape[0]
if pad > 0:
local_tensor = torch.cat([local_tensor,
torch.zeros(pad, dtype=local_tensor.dtype, device=device)])
# gather
gathered = [torch.zeros(max_size, dtype=local_tensor.dtype, device=device)
for _ in range(world_size)]
dist.all_gather(gathered, local_tensor)
# trim and concat on rank 0 only
if local_rank == 0:
return torch.cat([g[:all_sizes[i].item()]
for i, g in enumerate(gathered)]).cpu()
return None
def evaluate(model, loader, device):
model.eval()
pred_list, true_list = [], []
with torch.no_grad():
for data, targets in loader:
data = data.to(device)
pred = model(data)
pred_list.append(pred.detach()) # stay on GPU
true_list.append(targets.to(device)) # move labels to GPU too
local_preds = torch.cat(pred_list).ravel()
local_labels = torch.cat(true_list).ravel().float()
dist.barrier()
all_preds = distributed_gather_tensor(local_preds, device)
all_labels = distributed_gather_tensor(local_labels, device)
if local_rank == 0:
return auc_roc_score(all_labels.numpy(), all_preds.numpy())
return None
Configuration
Hyper-Parameters
batch_size_per_gpu = 64
imratio = 0.1 # for demo
total_epochs = 100
decay_epochs = [50, 75]
lr = 0.1
margin = 1.0
epoch_decay = 0.003 # refers gamma in the paper
weight_decay = 0.0001
sampling_rate = 0.2
Loading datasets
# load data as numpy arrays
train_data, train_targets = CIFAR10(root='./data', train=True).as_array()
test_data, test_targets = CIFAR10(root='./data', train=False).as_array()
# generate imbalanced data
generator = ImbalancedDataGenerator(verbose=True, random_seed=0)
(train_images, train_labels) = generator.transform(train_data, train_targets, imratio=imratio)
(test_images, test_labels) = generator.transform(test_data, test_targets, imratio=0.5)
# data augmentations
trainSet = ImageDataset(train_images, train_labels)
trainSet_eval = ImageDataset(train_images, train_labels, mode='test')
testSet = ImageDataset(test_images, test_labels, mode='test')
Construct DataLoaders
One of the key parts for distributed training is to use DistributedDualSampler as your train_sampler.
# dataloaders
train_sampler = DistributedDualSampler(trainSet, batch_size_per_gpu, sampling_rate=sampling_rate)
trainloader = torch.utils.data.DataLoader(trainSet, batch_size=batch_size_per_gpu, sampler=train_sampler, num_workers=2)
train_eval_sampler = DistributedSampler(trainSet_eval, shuffle=False, drop_last=False)
trainloader_eval = torch.utils.data.DataLoader(trainSet_eval, batch_size=batch_size_per_gpu, sampler=train_eval_sampler, num_workers=2)
test_sampler = DistributedSampler(testSet, shuffle=False, drop_last=False)
testloader = torch.utils.data.DataLoader(testSet, batch_size=batch_size_per_gpu,sampler=test_sampler, num_workers=2)
Creating Models & AUC Optimizer
For distributed training with LibAUC, it’s important to pass device as an argument to your loss function and optimzer.
# You can include sigmoid/l2 activations on model's outputs before computing loss
model = ResNet20(pretrained=False, last_activation=None, num_classes=1)
model = model.to(device)
model = DDP(model, device_ids=[local_rank])
loss_fn = AUCMLoss(device=device)
optimizer = PESG(model.parameters(),
loss_fn=loss_fn,
lr=lr,
momentum=0.9,
margin=margin,
epoch_decay=epoch_decay,
weight_decay=weight_decay,
device=device)
Training
Now it’s time for training. And we evaluate AUC performance after every epoch.
print ('Start Training')
print ('-'*30)
train_log = []
test_log = []
best_test = 0
for epoch in range(total_epochs):
if hasattr(train_sampler, 'set_epoch'):
train_sampler.set_epoch(epoch)
if epoch in decay_epochs:
optimizer.update_regularizer(decay_factor=10) # decrease learning rate by 10x & update regularizer
train_loss = []
model.train()
for data, targets in trainloader:
data, targets = data.to(device), targets.to(device)
y_pred = model(data)
y_pred = torch.sigmoid(y_pred)
loss = loss_fn(y_pred, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
# evaluation on train & test sets
train_auc = evaluate(model, trainloader_eval, device)
test_auc = evaluate(model, testloader, device)
if local_rank == 0:
train_loss_mean = np.mean(train_loss)
if best_test < test_auc:
best_test = test_auc
print("epoch: %s, train_loss: %.4f, train_auc: %.4f, test_auc: %.4f, "
"best_test_auc: %.4f, lr: %.4f"
% (epoch, train_loss_mean, train_auc, test_auc, best_test, optimizer.lr))
train_log.append(train_auc)
test_log.append(test_auc)
Visualization
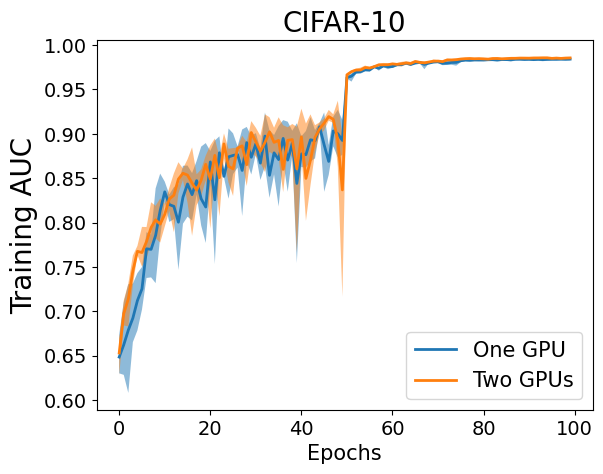
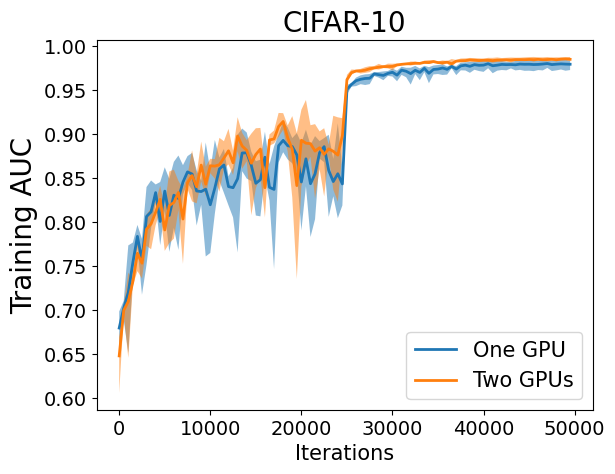
Now, let’s have a look at the learning curves for optimizing AUROC: the left figure compares one GPU (batch_size=128) with two GPUs (batch_size_per_gpu=64), while the right figure compares one GPU (batch_size=64) with two GPUs (batch_size_per_gpu=64).
|
|
Note
Below are key points to support distributed training with LibAUC.
Use
DistributedDualSampleras your train_sampler.Pass
deviceas an argument to your loss function and optimzer. For example,
loss_fn = AUCMLoss(device=device)
optimizer = PESG(model.parameters(),
loss_fn=loss_fn,
lr=lr,
momentum=0.9,
margin=margin,
epoch_decay=epoch_decay,
weight_decay=weight_decay,
device=device)