Training CLIP Models with FastCLIP
Introduction
In this tutorial, we will train a model using FastCLIP-v3, which optimizes a bimodal global contrastive loss with two learnable temperatures for images and texts, respectively. It employs a decay schedule for the moving average hyper-parameter gamma and a distributed framework. In pretraining stage, we use a subset of the CC3M dataset, which contains about 300,000 image-text pairs. And then we evaluate the pretrained models via zero-shot image/text retrieval on MS-COCO dataset. We provide the metadata of the training subset and evluation set here.
Reference
If you find this tutorial helpful in your work, please cite our library paper and the following paper:
@article{wei2024fastclip,
title={Fastclip: A suite of optimization techniques to accelerate clip training with limited resources},
author={Wei, Xiyuan and Ye, Fanjiang and Yonay, Ori and Chen, Xingyu and Sun, Baixi and Tao, Dingwen and Yang, Tianbao},
journal={arXiv preprint arXiv:2407.01445},
year={2024}
}
Importing required libs
!pip install -U libauc
!pip install timm
!pip install transformers
import os
os.environ["TOKENIZERS_PARALLELISM"] = "true"
import re
import argparse
from pathlib import Path
import json
import os
import random
import math
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
from torch import optim
import torchvision
from torchvision import transforms
from torch.utils.data import Dataset, Subset, DataLoader
from PIL import Image
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
Image.MAX_IMAGE_PIXELS = None
import cv2
import numpy as np
import timm
from transformers import AutoModel, AutoTokenizer
import libauc
from libauc.losses.contrastive import GCLoss_v2
from libauc.optimizers import SogCLR
from libauc.utils.paper_utils import CosineLRScheduler
Arguments for experiments
# path to data folder
data_path = './cc3m'
train_file = 'cc3m_subset_new.json'
# model config
image_encoder = 'resnet50'
text_encoder = 'distilbert-base-uncased'
image_res = 256
vision_width = 768
embed_dim = 256
seed = 42
# optimizer and schedular
opt = 'adamW'
lr = 3e-4
min_lr = 1e-5
warmup = True
warmup_lr = 1e-5
weight_decay = 0.02
decay_rate = 1
epochs = 30
warmup_epochs = 20
cooldown_epochs = 0
# training & test settings
batch_size_train = 1024
batch_size_test = 512
k_test = 256
# output path
output_dir = './output/'
# AMP training
use_amp = True
# loss config
temp = 0.07 # the temperature parameter for clip or sogclr
n_gpus = torch.cuda.device_count()
val_coco_file = 'coco_val_new.json'
test_coco_file = 'coco_test_new.json'
coco_image_root = './mscoco'
Path(output_dir).mkdir(parents=True, exist_ok=True)
Define helper functions
# we employ this function to preprocess the captions
def pre_caption(caption, max_words):
caption = re.sub(
r"([,.'!?\"()*#:;~])",
'',
caption.lower(),
).replace('-', ' ').replace('/', ' ').replace('<person>', 'person')
caption = re.sub(
r"\s{2,}",
' ',
caption,
)
caption = caption.rstrip('\n')
caption = caption.strip(' ')
#truncate caption
caption_words = caption.split(' ')
if len(caption_words)>max_words:
caption = ' '.join(caption_words[:max_words])
return caption
class train_set(Dataset):
def __init__(self, ann_file, transform, image_root, max_words=30):
self.ann = []
for f in ann_file:
self.ann += json.load(open(f,'r'))
self.transform = transform
self.image_root = image_root
self.max_words = max_words
self.img_ids = {}
n = 0
for ann in self.ann:
img_id = ann['image_id']
if img_id not in self.img_ids.keys():
self.img_ids[img_id] = n
n += 1
def __len__(self):
return len(self.ann)
def __getitem__(self, index):
ann = self.ann[index]
# image_path = os.path.join(self.image_root, ann['image'])
image_path = ann['image']
image = Image.open(image_path).convert('RGB')
image = self.transform(image)
caption = pre_caption(ann['caption'], self.max_words)
return image, caption, self.img_ids[ann['image_id']], index
class eval_set(Dataset):
def __init__(self, ann_file, transform, image_root, max_words=30):
self.ann = json.load(open(ann_file,'r'))
self.transform = transform
self.image_root = image_root
self.max_words = max_words
self.text = []
self.image = []
self.txt2img = {}
self.img2txt = {}
txt_id = 0
for img_id, ann in enumerate(self.ann):
self.image.append(ann['image'])
self.img2txt[img_id] = []
# 'val2014/000000184613.jpg'
image_path = os.path.join(self.image_root, ann['image'].split('/')[0], f"COCO_val2014_{ann['image'].split('/')[-1]}")
ann['image'] = image_path
for i, caption in enumerate(ann['caption']):
self.text.append(pre_caption(caption,self.max_words))
self.img2txt[img_id].append(txt_id)
self.txt2img[txt_id] = img_id
txt_id += 1
def __len__(self):
return len(self.image)
def __getitem__(self, index):
image_path = self.ann[index]['image']
image = Image.open(image_path).convert('RGB')
image = self.transform(image)
return image, index
def add_weight_decay(model, weight_decay=1e-5, skip_list=()):
decay = []
no_decay = []
for name, param in model.named_parameters():
if not param.requires_grad:
continue # frozen weights
if len(param.shape) == 1 or name.endswith(".bias") or name in skip_list:
no_decay.append(param)
else:
decay.append(param)
return [
{'params': no_decay, 'weight_decay': 0.},
{'params': decay, 'weight_decay': weight_decay}]
def create_optimizer(model, opt, weight_decay=1e-5, filter_bias_and_bn=True):
if weight_decay and filter_bias_and_bn:
skip = {}
if hasattr(model, 'no_weight_decay'):
skip = model.no_weight_decay()
parameters = add_weight_decay(model, weight_decay, skip)
weight_decay = 0.
else:
parameters = model.parameters()
opt_args = dict(lr=lr, weight_decay=weight_decay)
optimizer = SogCLR(parameters, mode=opt, **opt_args)
return optimizer
def create_scheduler(optimizer):
num_epochs = epochs
lr_scheduler = CosineLRScheduler(
optimizer,
t_initial = num_epochs,
t_mul = 1.0,
lr_min = min_lr,
decay_rate = decay_rate,
warmup_lr_init = warmup_lr,
warmup_t = warmup_epochs,
cycle_limit = 1,
t_in_epochs = True,
noise_range_t = None,
noise_pct = 0.67,
noise_std = 1.0,
noise_seed = 42,
)
return lr_scheduler
Reproducibility
The following functions limit the number of sources of randomness behaviors, such as model intialization, data shuffling, etcs.
# fix the seed for reproducibility
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
cudnn.benchmark = True
Building the model
# The following class includes the image encoder, text encoder and several objectives
class Model(nn.Module):
def __init__(self, image_encoder = None, text_encoder = None,
embed_dim = 256, init_model = True, bsz = 128,
gamma = 0.9, # the coefficient for moving average estimator
temp = 0.01, # temperature for clip or sogclr
gamma_schedule = 'cosine',
gamma_decay_epochs = 1,
):
super().__init__()
self.temp = temp
self.visual_encoder = timm.create_model(image_encoder, pretrained=init_model)
self.visual_encoder.reset_classifier(0)
self.text_encoder = AutoModel.from_pretrained(text_encoder, local_files_only=False)
if not init_model:
self.text_encoder.init_weights()
self.vision_proj = nn.Linear(self.visual_encoder.num_features, embed_dim)
self.text_proj = nn.Linear(768, embed_dim)
self.criterion = GCLoss_v2(tau=temp, gamma=gamma, enable_isogclr=False,
gamma_schedule=gamma_schedule, gamma_decay_epochs=gamma_decay_epochs,
temperature_scheme="global_learnable")
def forward(self, image, text_ids, text_att_masks, idx, text_idx, epoch):
image_embeds = self.visual_encoder(image)
image_embeds = self.vision_proj(image_embeds)
image_feat = F.normalize(image_embeds, dim=-1)
text_output = self.text_encoder(text_ids, attention_mask=text_att_masks, output_hidden_states=False)
text_embeds = self.text_proj(text_output.last_hidden_state[:,0,:])
text_feat = F.normalize(text_embeds, dim=-1)
loss, info = self.criterion(image_feat, text_feat, idx)
return loss, info
Training functions
print_freq = 50 # user can determine how many iterations to output (e.g., 50 by default)
def epoch_train(model, data_loader, optimizer, tokenizer, epoch, max_epoch, warmup_steps, device, scheduler, grad_scaler,
tau_optimizer, tau_lr_scheduler, tau_grad_scaler):
# train
model.train()
step_size = 100
warmup_iterations = warmup_steps * step_size
if hasattr(model, 'module'):
model_orig = model.module
else:
model_orig = model
# adjust gamma based on gamma schedule
if hasattr(model_orig.criterion, 'adjust_gamma'):
model_orig.criterion.adjust_gamma(epoch)
for i,(image, text, idx, text_idx) in enumerate(data_loader):
optimizer.zero_grad()
tau_optimizer.zero_grad()
image = image.to(device, non_blocking=True)
# idx = idx.to(device, non_blocking=True)
text_idx = text_idx.to(device, non_blocking=True)
text_input = tokenizer(text, padding='max_length', truncation=True, max_length=30, return_tensors="pt").to(device)
if grad_scaler is None:
loss, info = model(image, text_input.input_ids, text_input.attention_mask, idx=idx, text_idx=text_idx, epoch=epoch)
loss.mean().backward()
optimizer.step()
tau_optimizer.step()
else:
with torch.cuda.amp.autocast():
loss, info = model(image, text_input.input_ids, text_input.attention_mask, idx=idx, text_idx=text_idx, epoch=epoch)
grad_scaler.scale(loss.mean()).backward()
grad_scaler.step(optimizer)
grad_scaler.update()
tau_grad_scaler.scale(model_orig.criterion.tau.mean()).backward()
tau_grad_scaler.step(tau_optimizer)
tau_grad_scaler.update()
model_orig.criterion.tau.data.clamp_(0.01, 0.07)
if epoch==0 and i%step_size==0 and i<=warmup_iterations:
scheduler.step(i//step_size)
tau_lr_scheduler.step(i//step_size)
if i%print_freq == 0:
lr = optimizer.param_groups[0]["lr"]
print("Epoch:", epoch, "iteration:", i, "lr:", lr, "loss:", loss.mean().item(), "tau:", model_orig.criterion.tau.mean().item())
if info is not None:
print("tau_img: %.4f, tau_txt: %.4f" % (info[0].mean(), info[1].mean()))
Evaluation functions
@torch.no_grad()
def evaluation(model, data_loader, tokenizer, device):
# test
model.eval()
print('Computing features for evaluation...')
texts = data_loader.dataset.text
num_text = len(texts)
text_bs = 256
text_embeds = []
for i in range(0, num_text, text_bs):
text = texts[i: min(num_text, i+text_bs)]
text_input = tokenizer(text, padding='max_length', truncation=True, max_length=30, return_tensors="pt").to(device)
text_output = model.text_encoder(text_input.input_ids, attention_mask=text_input.attention_mask, output_hidden_states=False)
text_embed = F.normalize(model.text_proj(text_output.last_hidden_state[:,0,:]), dim=-1)
text_embeds.append(text_embed)
text_embeds = torch.cat(text_embeds,dim=0)
image_embeds = []
for image, img_id in data_loader:
image = image.to(device)
image_feat = model.visual_encoder(image)
image_embed = model.vision_proj(image_feat)
image_embed = F.normalize(image_embed, dim=-1)
image_embeds.append(image_embed)
image_embeds = torch.cat(image_embeds,dim=0)
sims_matrix = image_embeds @ text_embeds.t()
score_matrix_i2t = torch.full((len(data_loader.dataset.image),len(texts)),-100.0).to(device)
for i,sims in enumerate(sims_matrix):
topk_sim, topk_idx = sims.topk(k=k_test, dim=0)
score_matrix_i2t[i, topk_idx] = topk_sim
sims_matrix = sims_matrix.t()
score_matrix_t2i = torch.full((len(texts),len(data_loader.dataset.image)),-100.0).to(device)
for i,sims in enumerate(sims_matrix):
topk_sim, topk_idx = sims.topk(k=k_test, dim=0)
score_matrix_t2i[i, topk_idx] = topk_sim
return score_matrix_i2t.cpu().numpy(), score_matrix_t2i.cpu().numpy()
@torch.no_grad()
def itm_eval(scores_i2t, scores_t2i, txt2img, img2txt):
#Images->Text
ranks = np.zeros(scores_i2t.shape[0])
for index,score in enumerate(scores_i2t):
inds = np.argsort(score)[::-1]
# Score
rank = 1e20
for i in img2txt[index]:
tmp = np.where(inds == i)[0][0]
if tmp < rank:
rank = tmp
ranks[index] = rank
# Compute metrics
tr1 = 100.0 * len(np.where(ranks < 1)[0]) / len(ranks)
tr5 = 100.0 * len(np.where(ranks < 5)[0]) / len(ranks)
tr10 = 100.0 * len(np.where(ranks < 10)[0]) / len(ranks)
#Text->Images
ranks = np.zeros(scores_t2i.shape[0])
for index,score in enumerate(scores_t2i):
inds = np.argsort(score)[::-1]
ranks[index] = np.where(inds == txt2img[index])[0][0]
# Compute metrics
ir1 = 100.0 * len(np.where(ranks < 1)[0]) / len(ranks)
ir5 = 100.0 * len(np.where(ranks < 5)[0]) / len(ranks)
ir10 = 100.0 * len(np.where(ranks < 10)[0]) / len(ranks)
tr_mean = (tr1 + tr5 + tr10) / 3
ir_mean = (ir1 + ir5 + ir10) / 3
r_mean = (tr_mean + ir_mean) / 2
eval_result = {'txt_r1': tr1,
'txt_r5': tr5,
'txt_r10': tr10,
'txt_r_mean': tr_mean,
'img_r1': ir1,
'img_r5': ir5,
'img_r10': ir10,
'img_r_mean': ir_mean,
'r_mean': r_mean}
return eval_result
Dataset Pipeline for Bimodal Contrastive Learning
# set up the transformation, datasets and dataloaders
train_transform = transforms.Compose([
transforms.RandomResizedCrop(image_res, scale=(0.5, 1.0), interpolation=Image.BICUBIC),
transforms.RandomHorizontalFlip(),
transforms.RandAugment(),
transforms.ToTensor(),
transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
])
test_transform = transforms.Compose([
transforms.Resize((image_res, image_res), interpolation=Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
])
train_dataset = train_set([train_file], train_transform, data_path)
val_coco_dataset = eval_set(val_coco_file, test_transform, coco_image_root)
test_coco_dataset = eval_set(test_coco_file, test_transform, coco_image_root)
print("len of train_dataset:", len(train_dataset))
print("len of coco val/test:", len(val_coco_dataset), len(test_coco_dataset))
train_loader = DataLoader(train_dataset, batch_size=batch_size_train * n_gpus, num_workers=16, pin_memory=True,
shuffle=True, drop_last=True, prefetch_factor=4)
val_loader = DataLoader(val_coco_dataset, batch_size=batch_size_test, num_workers=16, pin_memory=True,
shuffle=False, drop_last=False, prefetch_factor=12)
test_loader = DataLoader(test_coco_dataset, batch_size=batch_size_test, num_workers=16, pin_memory=True,
shuffle=False, drop_last=False, prefetch_factor=12)
Pretraining and evaluation for SogCLR with Cosine Gamma
For consine gamma schedule, we recommend setting gamma_decay_epochs to 50% of the number of training epochs.
gamma = 0.2 # the parameter for the moving average estimator in sogclr/isogclr
# decaying from 1.0 to `gamma` (0.2)
gamma_schedule = "cosine"
gamma_decay_epochs = epochs // 2
# create the model and wrap it in DDP
tokenizer = AutoTokenizer.from_pretrained(text_encoder, local_files_only=False)
model = Model(image_encoder=image_encoder, text_encoder=text_encoder, embed_dim=embed_dim,
init_model=True, bsz=batch_size_train, gamma=gamma, temp=temp,
gamma_schedule=gamma_schedule, gamma_decay_epochs=gamma_decay_epochs)
model = model.cuda()
if n_gpus > 1:
print("Using", n_gpus, "GPUs")
model = nn.DataParallel(model)
# set up the optimizer and objective function
optimizer = create_optimizer(model, opt, weight_decay)
lr_scheduler = create_scheduler(optimizer)
tau_optimizer = torch.optim.AdamW([model.criterion.tau], lr=lr/4, weight_decay=0.0)
tau_lr_scheduler = create_scheduler(tau_optimizer)
if use_amp:
grad_scaler = torch.cuda.amp.GradScaler()
tau_grad_scaler = torch.cuda.amp.GradScaler()
else:
grad_scaler = None
tau_grad_scaler = None
# training loop
for epoch in range(0, epochs):
train_stats = epoch_train(model, train_loader, optimizer, tokenizer, epoch, epochs,
warmup_epochs, torch.device('cuda'), lr_scheduler, grad_scaler,
tau_optimizer, tau_lr_scheduler, tau_grad_scaler)
# evaluate the model on ms-coco data
try:
score_val_i2t_coco, score_val_t2i_coco = evaluation(model.module, val_loader, tokenizer, torch.device('cuda'))
score_test_i2t_coco, score_test_t2i_coco = evaluation(model.module, test_loader, tokenizer, torch.device('cuda'))
except:
# for non-distributed training
score_val_i2t_coco, score_val_t2i_coco = evaluation(model, val_loader, tokenizer, torch.device('cuda'))
score_test_i2t_coco, score_test_t2i_coco = evaluation(model, test_loader, tokenizer, torch.device('cuda'))
print("Epoch:", epoch)
val_result_coco = itm_eval(score_val_i2t_coco, score_val_t2i_coco, val_loader.dataset.txt2img, val_loader.dataset.img2txt)
print("coco val:", val_result_coco)
test_result_coco = itm_eval(score_test_i2t_coco, score_test_t2i_coco, test_loader.dataset.txt2img, test_loader.dataset.img2txt)
print("coco test:", test_result_coco)
lr_scheduler.step(epoch+warmup_epochs+1)
Visualization
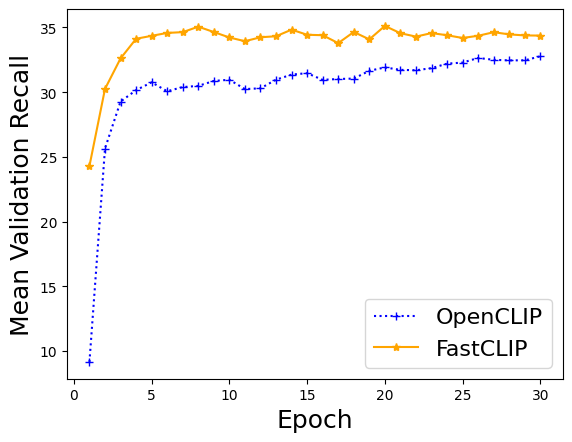
In order to compare the performance of different algorithms, we also train CLIP models using OpenCLIP, where the notebook is here. We plot the training curves of the mean validation recall values of the three algorithms.
clip_recall_vals = [9.146024256963882, 25.643747834199658, 29.270318539250965, 30.15803545248567, 30.758616553378648, 30.071351459416235, 30.393121418099422, 30.48455817672931, 30.86781287485006, 30.960474476875916, 30.23930161268826, 30.297093162734903, 30.965095295215246, 31.358384646141545, 31.467666266826605, 30.952405704384915, 31.01773290683726, 31.05107556977209, 31.651619352259097, 31.91153405304545, 31.72560575769692, 31.692890843662532, 31.85492869518859, 32.204224976675995, 32.286870585099294, 32.64414634146342, 32.50149940023991, 32.45683726509397, 32.46283220045315, 32.77081167532987]
fastclip_recall_vals = [24.293855791016924, 30.252612288417968, 32.606966546714645, 34.127257097161134, 34.355180594428894, 34.57910569105691, 34.640355857656935, 35.06099160335866, 34.64842729574836, 34.22647474343596, 33.93986405437825, 34.24375716380115, 34.322396374783416, 34.83299613487938, 34.437050513128085, 34.4030281220845, 33.790442489670795, 34.651717979474874, 34.08245635079302, 35.12101692656271, 34.557049180327866, 34.295081967213115, 34.567054511528724, 34.401079568172726, 34.18844328935093, 34.359738771158206, 34.63501666000267, 34.466374783419965, 34.38638011462082, 34.37372917499667]
import matplotlib.pyplot as plt
import numpy as np
epochs = np.arange(1, 31)
plt.plot(epochs, clip_recall_vals, label='OpenCLIP', ls=':', marker='+', color='blue')
plt.plot(epochs, fastclip_recall_vals, label='FastCLIP', marker='*', color='orange')
plt.ylabel('Mean Validation Recall', fontsize=18)
plt.xlabel('Epoch', fontsize=18)
plt.legend(fontsize=16)
plt.show()